Stable instability – an oxymoron or a necessity?
Industrialization is raging in the IT field. There is nothing wrong with that, and even sometimes it is justified. Division of labor, planning, etc. The problem is that the industrial era has provoked the emergence of a large number of narrow specialists in IT who do not have a broad view of the task / system that they develop or maintain. They are not to blame for this. But a specialist must have a “broad view of the world” and, along with his main specialization, at least superficially understand the neighboring areas. Such people are called allrounder or “multi-instrumentalists” (playing different instruments)
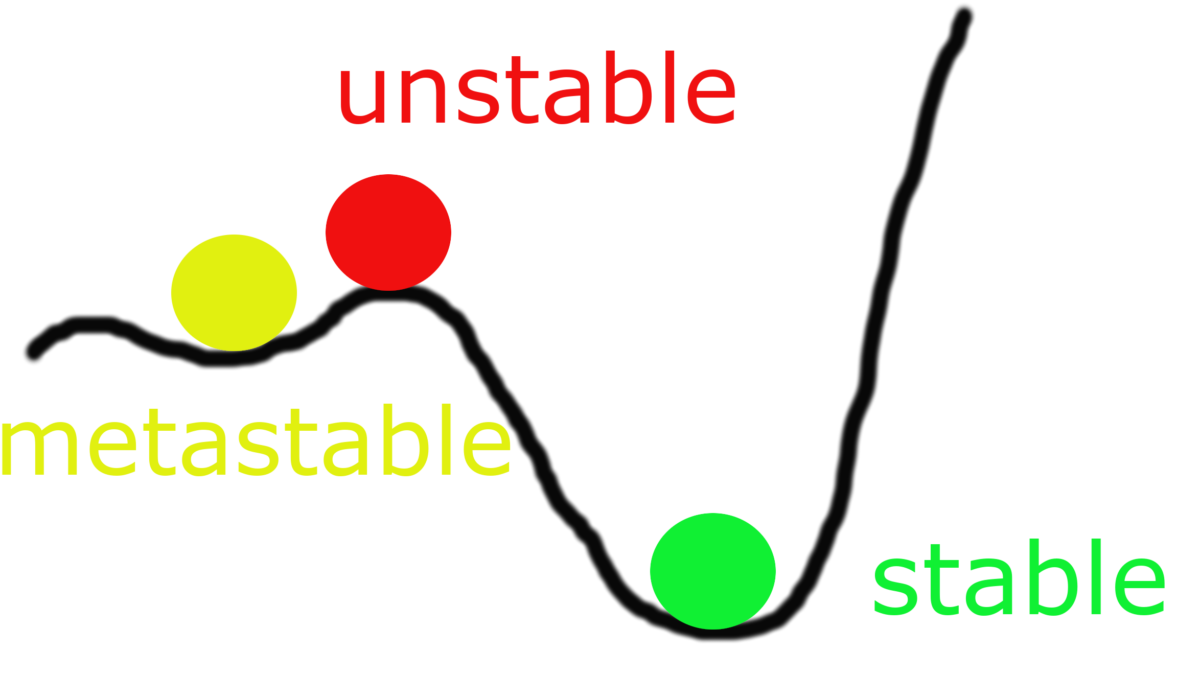
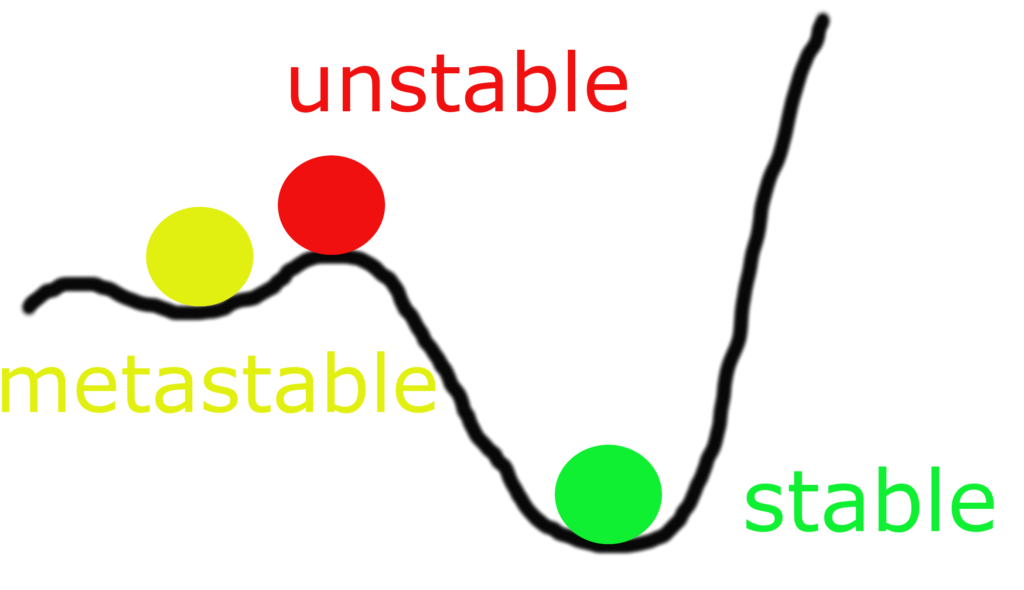
But let’s move from macroeconomics and psychology to technology and try to justify why you shouldn’t just reboot servers when problems arise with them. Let’s take it as an axiom that the system initially worked well and performed its functions. Those. was in stable condition. It is worth clarifying and determining at least 3 possible states of the system:
- stable (everything works as it should)
- metastable (works, but according to the principle “never touch a running system”)
- unstable (everything is bad)
Normally operating systems are either in a stable or, more often, in a metastable state.
Then something happened and the system went into an unstable state. At this stage, usually after a couple of reboots, people come to you and ask to see what doesn’t work there.
Here I will introduce two more important terms. System states as a subset of unstable:
- stably unstable (or stably unstable)
- unstable unstable
Stable unstable or persistently unstable state of the system
The most important point. We know for sure that the system is not working as it should, but we do not know why. In this state, we have the opportunity to look at the logs, talk to people (developers, network engineers and users), accumulate observations for further judgments and conclusions. The main thing is not to destabilize a stably unstable system! This is my slogan at this stage. The most basic and favorite way of destabilization, or in other words, transferring the system to an unstable unstable state, is reboot.
A simple example from life. The system was malfunctioning. After numerous reboots, the problem disappeared and they put it on my face, they say it helps, and you tell us fairy tales here. True, at the same time, strange artifacts appeared in the form of client sessions freezing and data loss (sometimes). The problem reappeared sporadically, again at the worst possible moment, usually on the weekend. It turned out that they had messed up with the rotation of the logs and the disk was overflowing. When rebooting, the temporary section was freed and everything somehow worked for a while. Until it overflowed again. Of course, they forgot to monitor this section. As a solution, we simply tweaked the log rotation algorithm in about 5 minutes.
You need to clearly understand the main goal of troubleshooting – to determine the source of unbalancing the system and return it to a stable state. Misinterpretations often come through. Many are afraid to admit a mistake, and sometimes even try to hide it. It should be added here that those responsible for the system sometimes try to find or even appoint someone to blame. This is all very harmful to the common cause. It turns out that one cannot do without psychology in troubleshooting.
Let’s summarize. For success in troubleshooting, you need to:
- be brave and confess your mistakes. This is 50% of success on the way to the goal.
- keep an unstable system in a stable unstable state
- look for a fault
Everything is like in life!
{kind=link}
{kind=link}