
Core Data + Repository pattern. Implementation details
The main idea of the repository is to abstract from data sources, hide implementation details, because, from the point of view of data access, this very implementation does not matter. Providing access to the main operations on data: save, load or delete is the main task of the repository.
Its advantages include:
- no dependencies on the repository implementation. Anything can be under the hood: an in-memory collection, UserDefaults, KeyChain, Core Data, Realm, URLCache, a separate tmp file, etc.;
- division of areas of responsibility. The repository acts as a layer between the business logic and the way data is stored, separating one from the other;
- formation of a unified, more structured approach to working with data.
Ultimately, all this favorably affects the speed of development, scalability and testability of projects.
To the details
Consider the worst-case scenario for using Core Data.
For a general understanding, we will use the DataProvider class (hereinafter referred to as DP) – its task is to receive data from somewhere (network, UI) and put it in the Repository. Also, if necessary, DP can get data from the repository, acting as a facade for it. By data we mean an array of domain objects. It is with them that the repository operates.
1.Core Data as one big repository with NSManagamentObject
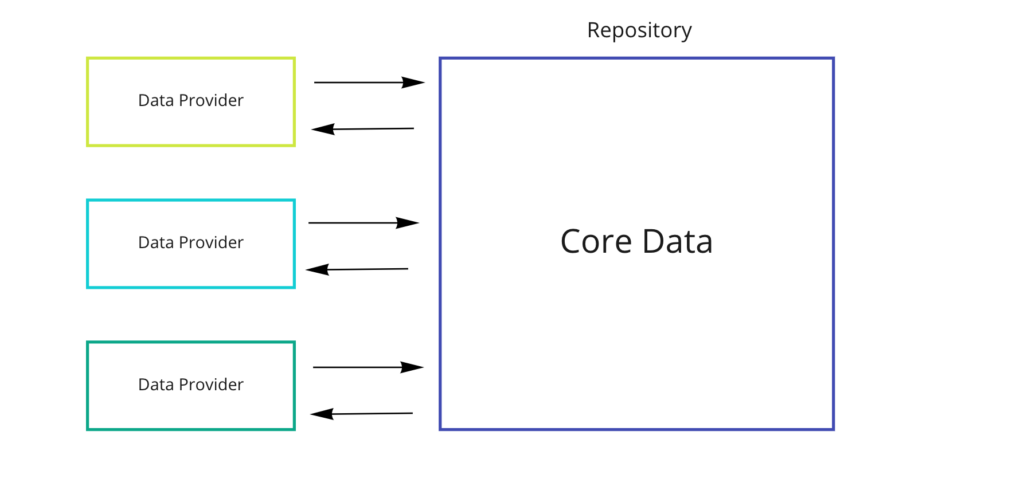
The idea of operating NSManagedObject as a domain object is the simplest, but not the most successful one. With this approach, we face several problems at once:
- Core Data grows throughout the project, hanging unnecessary dependencies and violating areas of responsibility. Details of the implementation are disclosed. Know what the implementation of the repository is tied to – only the repository should;
- Using a single repository for all Data Providers, it will grow with the appearance of new domain objects;
- In the worst case, the logic of working with objects will start to overlap and this can turn into one big unpredictable magic.
2. Core Data + DB Client
The first thing that comes to mind to solve the problems from the previous example is to move the logic of working with objects into a separate class (let’s call it DB Client), then our Repository will only save and retrieve objects from the repository, while all the logic on work with objects will lie in the DB Client. The output should look something like this:
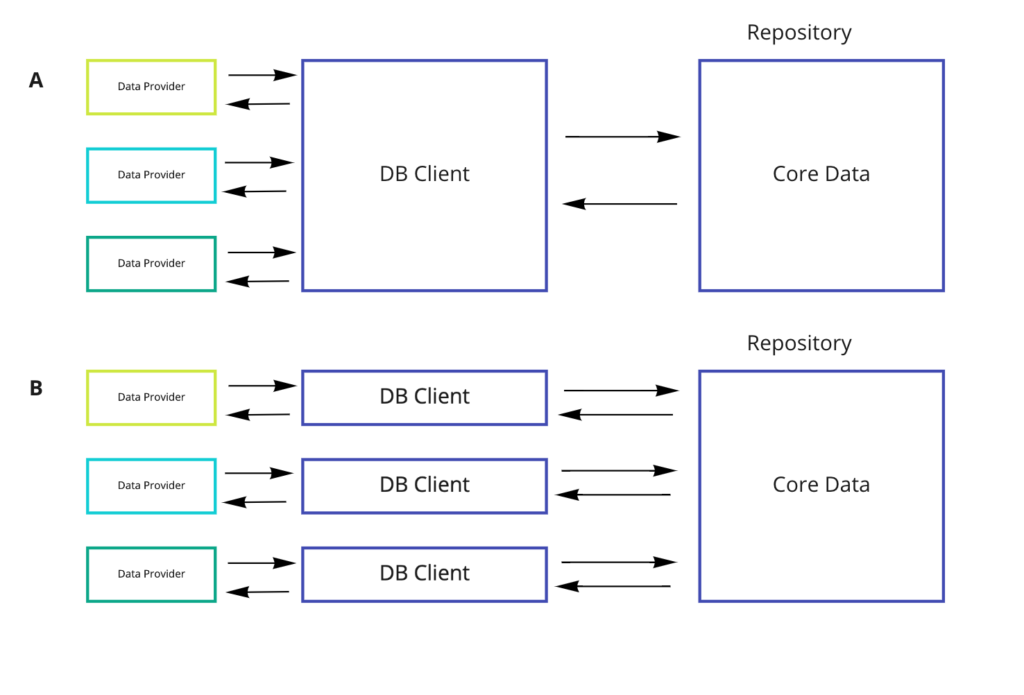
Both schemes solve problem # 1. (Core Data is limited to DB Client and Repository), and can partially solve problem # 2 and # 3 on small projects, but do not completely exclude them. Continuing the thought further, it is possible to come to the following scheme:
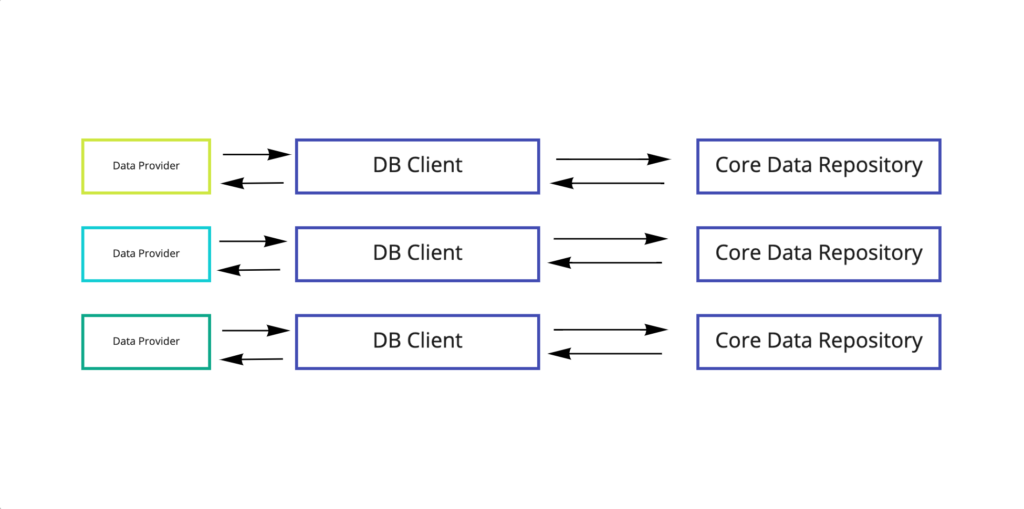
- Core Data can only be limited to a repository. DB Client converts domain objects to NSManagedObject and vice versa;
- The Repository is no longer one and does not grow;
- Data processing logic is more structured and consolidated
Here, it is worth noting that there are many options for composition and decomposition of classes, as well as ways of organizing interaction between them. Nevertheless, the above-described scheme shows another important problem: for each new domain object, at best, it is required to create X2 objects (DB Client and Repository). Therefore, we will consider another way of implementation.
Preparation for implementation
This is how the repository looks like:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
protocol AccessableRepository { //1 associatedtype DomainModel //2 var actualSearchedData: Observable<[DomainModel]>? {get} //3 func save(_ objects: [DomainModel], completion: @escaping ((Result<Void>) -> Void)) //4 func save(_ objects: [DomainModel], clearBeforeSaving: RepositorySearchRequest, completion: @escaping ((Result<Void>) -> Void)) //5 func present(by request: RepositorySearchRequest, completion: @escaping ((Result<[DomainModel]>) -> Void)) //6 func delete(by request: RepositorySearchRequest, completion: @escaping ((Result<Void>) -> Void)) //7 func eraseAllData(completion: @escaping ((Result<Void>) -> Void)) } |
- Domain object operated by the repository;
- The ability to subscribe to tracking changes in the repository;
- Saving objects to the repository;
- Saving objects with the ability to clean up old data within the same context;
- Loading data from the repository;
- Removing objects from the repository;
- Removing all data from the repository.
Perhaps your set of requirements for the repository will be different, but conceptually this will not change the situation.
Unfortunately, the ability to work with the repository through the AccessableRepository is missing, as evidenced by this error:

In this case, the Generic implementation of the repository is well suited, which looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
class Repository<DomainModel>: NSObject, AccessableRepository { typealias DomainModel = DomainModel var actualSearchedData: Observable<[DomainModel]>? { fatalError("actualSearchedData must be overrided") } func save(_ objects: [DomainModel], completion: @escaping ((Result<Void>) -> Void)) { fatalError("save(_ objects: must be overrided") } func save(_ objects: [DomainModel], clearBeforeSaving: RepositorySearchRequest, completion: @escaping ((Result<Void>) -> Void)) { fatalError("save(_ objects vs clearBeforeSaving: must be overrided") } func present(by request: RepositorySearchRequest, completion: @escaping ((Result<[DomainModel]>) -> Void)) { fatalError("present(by request: must be overrided") } func delete(by request: RepositorySearchRequest, completion: @escaping ((Result<Void>) -> Void)) { fatalError("delete(by request: must be overrided") } func eraseAllData(completion: @escaping ((Result<Void>) -> Void)) { fatalError("eraseAllData(completion: must be overrided") } } |
- NSObject is needed to interact with NSFetchResultController;
- AccessableRepository – for clarity, transparency, and order;
- FatalError acts as a safeguard so that anyone who enters here does not use what is not implemented;
This solution allows you not to be tied to a specific implementation, and also to get around the previous problem:

To work with a selection of objects, you need an object with two properties:
|
1 2 3 4 5 6 7 8 9 |
protocol RepositorySearchRequest { /* NSPredicate = nil, apply for all records for deletion sortDescriptor is not Used */ //1 var predicate: NSPredicate? {get} //2 var sortDescriptors: [NSSortDescriptor] {get} } |
- Selection condition, if the condition is absent, the selection is applied to the entire data set;
- Sorting condition – can be either absent or present.
Since, in the future, it may be necessary to use a separate NSPersistentContainer (for example, for testing), which, in turn, acts as a source of the context – you need to close it with a protocol:
|
1 2 3 4 5 6 |
protocol DBContextProviding { //1 func mainQueueContext() -> NSManagedObjectContext //2 func performBackgroundTask(_ block: @escaping (NSManagedObjectContext) -> Void) } |
- The context with which the main Queue operates is required to use the NSFetchedResultsController;
- Required to perform data operations on a background thread. Can be replaced with newBackgroundContext(). You can read about the differences in the work of these two methods here.
Also, you will need objects that will convert (mapping) domain models to repository objects (NSManagedObject) and vice versa:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
class DBEntityMapper<DomainModel, Entity> { //1 func convert(_ entity: Entity) -> DomainModel? { fatalError("convert(_ entity: Entity: must be overrided") } //2 func update(_ entity: Entity, by model: DomainModel) { fatalError("supdate(_ entity: Entity: must be overrided") } //3 func entityAccessorKey(_ entity: Entity) -> String { fatalError("entityAccessorKey must be overrided") } //4 func entityAccessorKey(_ object: DomainModel) -> String { fatalError("entityAccessorKey must be overrided") } } |
- Allows you to convert NSManagedObject to a domain model;
- Allows updating NSManagedObject using the domain model;
- Used for communication between NSManagedObject and domain object.
You can use a domain object as an NSManagedObject initializer. On the one hand, it is convenient, but on the other hand, it imposes a number of restrictions. For example, when links between objects are used and one NSManagedObject creates several other NSManagedObject. This approach blurs areas of responsibility and negatively affects the overall logic of working with data.
While working with the repository, you will need to handle errors, an enum is enough for this:
|
1 2 3 4 |
enum DBRepositoryErrors: Error { case entityTypeError case noChangesInRepository } |
Here the abstract part of the repository comes to an end, the most interesting thing remains – the implementation.
Implementation
For this example, a simple DBContextProvider implementation (without any additional parameters) will do:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
final class DBContextProvider { //1 private lazy var persistentContainer: NSPersistentContainer = { let container = NSPersistentContainer(name: "DataStorageModel") container.loadPersistentStores(completionHandler: { (_, error) in if let error = error as NSError? { fatalError("Unresolved error \(error),\(error.userInfo)") } container.viewContext.automaticallyMergesChangesFromParent = true }) return container }() //2 private lazy var mainContext = persistentContainer.viewContext } //3 //MARK:- DBContextProviding implementation extension DBContextProvider: DBContextProviding { func performBackgroundTask(_ block: @escaping (NSManagedObjectContext) -> Void) { persistentContainer.performBackgroundTask(block) } func mainQueueContext() -> NSManagedObjectContext { self.mainContext } } |
- Initializing NSPersistentContainer;
- Previously, this approach eliminated memory leaks;
- DBContextProviding implementation.
The main part of the repository looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
final class DBRepository<DomainModel, DBEntity>: Repository<DomainModel>, NSFetchedResultsControllerDelegate { //1 private let associatedEntityName: String //2 private let contextSource: DBContextProviding //3 private var fetchedResultsController: NSFetchedResultsController<NSFetchRequestResult>? //4 private var searchedData: Observable<[DomainModel]>? //5 private let entityMapper: DBEntityMapper<DomainModel, DBEntity> //6 init(contextSource: DBContextProviding, autoUpdateSearchRequest: RepositorySearchRequest?, entityMapper: DBEntityMapper<DomainModel, DBEntity>) { self.contextSource = contextSource self.associatedEntityName = String(describing: DBEntity.self) self.entityMapper = entityMapper super.init() //7 guard let request = autoUpdateSearchRequest else { return } self.searchedData = .init(value: []) //self.fetchedResultsController = configureactualSearchedDataUpdating(request) } } |
- The property that will be used when working with NSFetchRequest;
- DBContextProviding – to access the context, it is required to perform save, load, delete operations;
- fetchedResultsController – required when you want to track changes in the NSPersistentStore (changes to objects in the database);
- searchedData – Depends on fetchedResultsController and wraps the fetchedResultsController, hiding implementation details and notifying subscribers of data changes.
- entityMapper – converts domain objects to NSManagedObject and vice versa;
- Initializer;
- If autoUpdateSearchReques != nil, execute fetchedResultsController configuration to track changes in the database;
In order not to generate the same type of code for working with the context, you need a helper method:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
private func applyChanges(context: NSManagedObjectContext, mergePolicy: Any = NSMergeByPropertyObjectTrumpMergePolicy, completion: ((Result<Void>) -> Void)? = nil) { //1 context.mergePolicy = mergePolicy switch context.hasChanges { case true: do { //2 try context.save() } catch { ConsoleLog.logEvent(object: "DBRepository \(DBEntity.self)", method: "saveIn", "Error: \(error)") completion?(Result.error(error)) } ConsoleLog.logEvent(object: "DBRepository \(DBEntity.self)", method: "saveIn", "Saving Complete") completion?(Result(value: ())) case false: //3 ConsoleLog.logEvent(object: "DBRepository \(DBEntity.self)", method: "saveIn", "No changes in context") completion?(Result(error: DBRepositoryErrors.noChangesInRepository)) } } |
- mergePolicy – Responsible for how conflicts are resolved when working with the context. In this case, the default policy is to give priority to modified objects in memory over persistent store;
- Saving changes to the persistent store;
- If there are no object changes, a corresponding error is passed to the completion block.
Saving objects is implemented as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
private func saveIn(data: [DomainModel], clearBeforeSaving: RepositorySearchRequest?, completion: @escaping ((Result<Void>) -> Void)) { contextSource.performBackgroundTask() { context in //1 if let clearBeforeSaving = clearBeforeSaving { let clearFetchRequest = NSFetchRequest<NSManagedObject>(entityName: self.associatedEntityName) clearFetchRequest.predicate = clearBeforeSaving.predicate clearFetchRequest.includesPropertyValues = false (try? context.fetch(clearFetchRequest))?.forEach({ context.delete($0) }) } //2 var existingObjects: [String: DBEntity] = [:] let fetchRequest = NSFetchRequest<NSManagedObject>(entityName: self.associatedEntityName) (try? context.fetch(fetchRequest) as? [DBEntity])?.forEach({ let accessor = self.entityMapper.entityAccessorKey($0) existingObjects[accessor] = $0 }) data.forEach({ let accessor = self.entityMapper.entityAccessorKey($0) //3 let entityForUpdate: DBEntity? = existingObjects[accessor] ?? NSEntityDescription.insertNewObject(forEntityName: self.associatedEntityName, into: context) as? DBEntity //4 guard let entity = entityForUpdate else { return } self.entityMapper.update(entity, by: $0) }) //5 self.applyChanges(context: context, completion: completion) } } |
- It is used when it is necessary to delete objects, before saving new ones (within the current context);
- Objects that exist in the repository are unloaded for further modification;
- If there is no entity with the desired entityAccessorKey, a new NSManagedObject instance is created;
- Mapping properties from the domain object to the NSManagedObject;
- Applying the changes made.
Important: This solution is optimal for small datasets. For large data sets, it is recommended to split them into parts, use batchUpdate and batchDelete, and starting with IOS 13 batchInsert appeared.
Thus, the implementation of the save methods is reduced to calling the saveIn method:
|
1 2 3 4 5 6 |
override func save(_ objects: [DomainModel], completion: @escaping ((Result<Void>) -> Void)) { saveIn(data: objects, clearBeforeSaving: nil, completion: completion) } override func save(_ objects: [DomainModel], clearBeforeSaving: RepositorySearchRequest, completion: @escaping ((Result<Void>) -> Void)) { saveIn(data: objects, clearBeforeSaving: clearBeforeSaving, completion: completion) } |
The present, delete, eraseAllData methods are tied to working with NSFetchRequest. There is nothing special about their implementation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
override func present(by request: RepositorySearchRequest, completion: @escaping ((Result<[DomainModel]>) -> Void)) { //1 let fetchRequest = NSFetchRequest<NSManagedObject>(entityName: associatedEntityName) fetchRequest.predicate = request.predicate fetchRequest.sortDescriptors = request.sortDescriptors contextSource.performBackgroundTask() { context in do { //2 let rawData = try context.fetch(fetchRequest) guard rawData.isEmpty == false else {return completion(Result(value: [])) } guard let results = rawData as? [DBEntity] else { completion(Result(value: [])) assertionFailure(DBRepositoryErrors.entityTypeError.localizedDescription) return } //3 let converted = results.compactMap({ return self.entityMapper.convert($0) }) completion(Result(value: converted)) } catch { completion(Result(error: error)) } } } override func delete(by request: RepositorySearchRequest, completion: @escaping ((Result<Void>) -> Void)) { //1 let fetchRequest = NSFetchRequest<NSManagedObject>(entityName: associatedEntityName) fetchRequest.predicate = request.predicate fetchRequest.includesPropertyValues = false contextSource.performBackgroundTask() { context in //2 let results = try? context.fetch(fetchRequest) results?.forEach({ context.delete($0) }) //3 self.applyChanges(context: context, completion: completion) } } override func eraseAllData(completion: @escaping ((Result<Void>) -> Void)) { //1 let fetchRequest = NSFetchRequest<NSFetchRequestResult>(entityName: associatedEntityName) let batchDeleteRequest = NSBatchDeleteRequest(fetchRequest: fetchRequest) batchDeleteRequest.resultType = .resultTypeObjectIDs contextSource.performBackgroundTask({ context in do { //2 let result = try context.execute(batchDeleteRequest) guard let deleteResult = result as? NSBatchDeleteResult, let ids = deleteResult.result as? [NSManagedObjectID] else { completion(Result.error(DBRepositoryErrors.noChangesInRepository)) return } let changes = [NSDeletedObjectsKey: ids] NSManagedObjectContext.mergeChanges( fromRemoteContextSave: changes, into: [self.contextSource.mainQueueContext()] ) //3 completion(Result(value: ())) return } catch { ConsoleLog.logEvent(object: "DBRepository \(DBEntity.self)", method: "eraseAllData", "Error: \(error)") completion(Result.error(error)) } }) |
- Creation of a request;
- Selection of objects and their processing;
- Return of the result of the operation.
To implement the ability to track data changes in real-time, you need a FetchedResultsController. The following method is used to configure it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
private func configureactualSearchedDataUpdating(_ request: RepositorySearchRequest) -> NSFetchedResultsController<NSFetchRequestResult> { //1 let fetchRequest: NSFetchRequest<NSFetchRequestResult> = NSFetchRequest(entityName: associatedEntityName) fetchRequest.predicate = request.predicate fetchRequest.sortDescriptors = request.sortDescriptors //2 let fetchedResultsController = NSFetchedResultsController(fetchRequest: fetchRequest, managedObjectContext: contextSource.mainQueueContext(), sectionNameKeyPath: nil, cacheName: nil) //3 fetchedResultsController.delegate = self try? fetchedResultsController.performFetch() if let content = fetchedResultsController.fetchedObjects as? [DBEntity] { updateObservableContent(content) } return fetchedResultsController } func updateObservableContent(_ content: [DBEntity]) { let converted = content.compactMap({ return self.entityMapper.convert($0) }) //4 searchedData?.value = converted } |
- Formation of a request on the basis of which changes will be tracked;
- Creating an instance of the NSFetchedResultsController class;
- performFetch () allows you to execute a request and get data without waiting for changes in the database. For example, this can be useful when implementing Ofline First;
- Changing the searchedData property, in turn, notifies subscribers (if any) of the change.
Conclusion
At this stage, the implementation of all the basic methods for working with the repository comes to an end. The main advantages are:
- the logic of work of the repository with Core Data has become the same everywhere;
- to add new objects to the repository, it is enough to create only the EntityMapper (a new Entity must be created in any case). All property mapping logic is also collected in one place;
- The data layer has become more structured. You can now make sure that the repository does not make a huge number of requests in the save method to establish relationships between objects;
- the repository can be easily changed, for example, for tests, or for debugging.
This approach may not suit everyone, and this is its main disadvantage. Often, the logic of working with data depends on the back-end as well.


{kind=link}
{kind=link}
{kind=link}