
CI / CD: how we build and test our games
The team should focus on creating beautiful and successful games, for everything else there is CI.
Where do we apply CI? What approaches and concepts do we use? Why do we build and test builds? The detailed story about CI and how it is organized in our company you can find below.
First, a little warm-up: what is Continuous Integration? If the team uses the repository and collects night builds – is this CI already? What is the difference between Continuous Deployment and Delivery? It is almost unimportant. Details are needed only for a narrow circle of specialists. If you want to involve the whole company in some process, come up with a simple and good name for it. In AppSoft, we call all these approaches CI.
Idea
CI is not a goal, it is a tool. There must be a goal that you want to achieve with Continuous Integration, a problem that needs to be solved. It happens that the development and release processes in a team are built on the principle of “pray and put in production.” Sometimes it is justified, but infrequently.
We formulated our goal as follows: to minimize the likelihood of integration problems, to minimize the resources required to correct the errors found, to reduce the time of project development teams to support CI processes.
CI is the automation of build processes, code testing and its delivery to various environments, automation of routine development processes, mutual integration of services that we all use.
The idea is in a system that automatically collects everything, does it often, tests and delivers a build, and also targetedly reports a convenient data if something goes wrong.
Where do we apply CI?
- Engine and utilities,
- our games for all platforms,
- server code
- analytics, marketing services, various automation, CI services,
- infrastructure.
So everywhere or almost everywhere.
Assembling and testing containers, automatic deployments in Test, Staging and Production, Rolling and Canary updates – all of this we already know. Today we will focus on CI for games: how to build builds, test them and deliver them.
Paradigms
To achieve the goals stated above, you need to solve several problems. Below is the plan we are following when we automate some process in development, for example, assembling a mobile game client. It is very convenient to have a list of questions, answering which you can solve any problem that comes into the CI team.
Documentation
Build assembly instructions are documentation, a description of our automated process. Often such documentation is in the head of programmers. If the team has a super-specialist in building builds and without it, nobody can build the build quickly and without errors anymore – it’s time to change something, there will be no submission.
Well, if such documentation is framed in the form of a script:
I entered a command line and a set of parameters on a machine with a prepared environment – I got a build.
The best process documentation is the code. Even if for some reason you need to repeat the operation manually, you can always do it by looking into it.
Logging
The build log allows you to always say for sure: who, when, from which commit, and with what result this or that build was collected. We look in the log, we find the first floppy build, we see the list of commits that got there – profit.
The log is even more useful when it comes, for example, to server code. If there is no information about who updated the prod and when, then in the general case it is not known which code is currently working there. And sometimes it is very important, very.
You can keep such a journal in ledger, preferably in a table or wiki. The list of builds in the CI system is priceless.
Security
When it comes to building the build and deploying it to some environment, the question always arises: where to store login / access passwords? Them you usually need a lot: to the repository to download the source data, to the file storage to fill in the game resources, to HockeyApp to send characters, to the server to update the code, etc.
It happens that all the necessary accesses are stored in the repository. There is a hypothesis that this is not very good. Often you can see the “enter password” field, lets say, in Jenkins, where the author of the build enters the hidden characters.
Remembering all passwords is a good skill. Our CI server itself receives the necessary accesses depending on the assembly. Usually, these are short-lived tokens that are generated at the start of the build and give minimal rights exactly where we deploy something or where we read something from.
Centralized management of the assembly and deployment allows you to solve the problem of differentiating access rights to the infrastructure. Why give someone access to the server if you can only give access to the assembly of the corresponding build that does the necessary operation on this server? And since there is a build, then we have documentation and journaling, well, you understand.
Traceability
There are usually a lot of traces left during build time. No, not like that: during build it is necessary to leave as many traces as possible. In the repository, in the task tracker, in the build distribution system. Everywhere, wherever you encounter a build, there should be traces that lead you to complete information about it.
These traces do not need to be swept away, on the contrary, they must be carefully left and carefully preserved. Next I will talk about this in more detail, but first we need to collect our build.
Pre-commit hooks
I repeat, the idea is a system that collects, tests and reports everything. But why create a build if you don’t need to build it?
All developers of our games have pre-commit hooks installed, i.e. a set of checks that are performed when trying to commit something. Checks are run only for modified files, but we implemented a very tricky cross-dependency search system to check all related content too. Those if the artist added a texture, then hooks will check that they have not forgotten to register it wherever needed, and made it without mistakes.
It turns out that hooks catch a significant part of small errors. They save the resources of the build system and help the developer quickly fix the problem: he sees a message that says in detail what went wrong. And he does not need to switch between tasks: he literally just made changes and is in context. Error correction time is minimal.
We liked it so much that we even made a system that checks if hooks were made for a commit that got into the repository. If not, the author of such a commit will automatically receive a task asking them to configure them and detailed instructions on how to do this.
Hooks are standardized for all projects. The number of custom tests is minimal. There is convenient customization, including depending on the user who is running: this is very convenient for testing tests.
Build
To see the problem in the build as early as possible, you need to collect and test these builds as often as possible. Clients of our games are made for all platforms, for each commit, for all projects. There are probably some exceptions, but not many.
Typically, a client, especially a mobile one, has several different versions: with and without cheats, differently signed, etc. For each commit, we collect “regular” builds, which developers and testers use constantly.
There are builds that are used very rarely, for example, the store ios build – only once in a submission, i.e. about once a month. However, we believe that all builds should be collected regularly. If a problem occurs with this type of assembly, on the development or infrastructure side, the project team will know about it not on the day the build is delivered, but much earlier, and will be able to respond and fix the problem in advance.
As a result, we have a simple rule: any build is launched at least once a day. The project development team will find out about the presence of any problems on any platform in the worst case in the morning after this problem appears in the repository.
Such a frequency of assemblies and tests requires a special approach to optimizing their execution time.
- All regular client builds are incremental.
- Atlas packaging and resource preparation are also incremental.
- Assemblies are granular: some of the steps are in separate build configurations – this allows you to execute them in parallel, as well as reuse intermediate results.
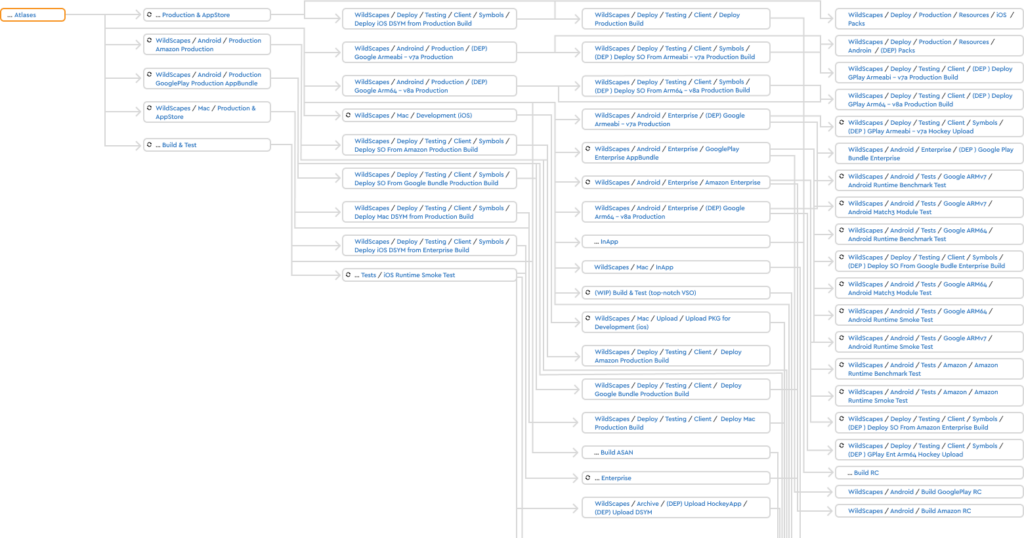
This is an almost complete screenshot of the chain of builds and tests for WildScapes.
Static Tests
After the assembly, static testing is performed: we take the build folder and perform a set of checks of all the content that is there. Code is also content, so its static analysis (cppcheck + PVS-Studio) is also here.
I emphasize only that the static tests after the build and in the pre-commit hooks are performed by the same code. This greatly simplifies system support.
Runtime tests
If the static tests build was successful, you can go ahead and try to run the assembled build. We are testing builds on all platforms except UWP, i.e. Windows, MacOs, iOS, Android. UWP – will also be, but a little later.
Why test desktop builds if they seem to be needed only in development? The answer to the question is: it is bad if the artist or designer receives a build that crashes upon launch for some ridiculous reason. Therefore, Smoke-Test, the minimum set of checks for runability and basic gameplay, is performed for all platforms.
Everything that was written above about builds is also true for tests on devices – at least once a day. With few exceptions: there are very long tests that do not have time to complete in a day.
Smoke-tests run on every commit. Successful completion of basic checks is a prerequisite for the build to get into the distribution system. Usually it makes no sense to give someone access to a build that obviously doesn’t work. Here you can object and come up with exceptions. Projects have a workaround to give access to a non-working build, but they hardly use it.
Which other tests are there:
- Benchmark: we check performance on FPS and memory in various situations and on all devices.
- Match-3 unit tests: each element and each mechanics are tested both individually and in all combinations of interaction.
- The passage of the entire game from start to finish.
- Various regression tests, for example, localization tests, or that all UI windows open correctly, or that fishdom scenes in Fishdom play without errors.
- All the same, but with AddressSanitizer.
- Compatibility tests for game versions: we take the user’s save file from previous versions, open it in the new version and make sure that everything is fine.
- Various custom tests relevant to the mechanic of a particular project.
To run the tests, we use our own test stand of iOS and Android devices. This allows us to flexibly launch the builds we need on devices, interact with the device from the code. We have full control, an understandable level of reliability, we know what problems we may face and how long it will take to solve them. None of the cloud services that provide testing devices offers such comfort.
CATS
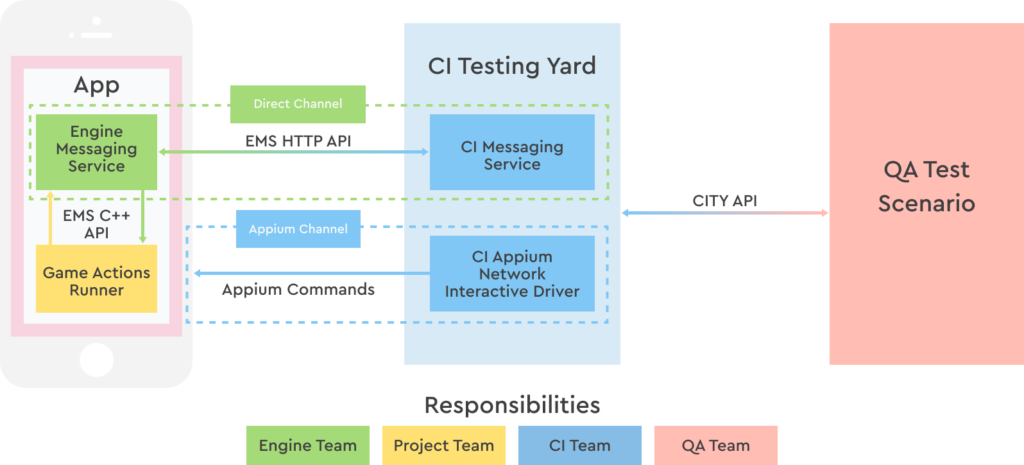
The tests listed above are implemented inside the project code. This allows in theory to make a test of any complexity, but requires effort and resources from the development of the project to implement and support these tests. These resources are often not available, and testing multiple regression by hand is difficult and not necessary. I really wanted the testers themselves to do test automation. And we came up with a framework for them – the Continuous Automation Testing System, or CATS.
What is the idea: to enable test script authors to interact with the gaming application, absolutely not caring about how it all works. We write scripts in primitive python, we appeal to the application through a set of abstractions. For example: “Homescapes, open me a shopping window and buy such and such a product.” Check the result, bingo.
The entire implementation of script commands is hidden behind a set of abstractions. The API that implements interaction with the application allows you to do any action in several ways:
- send an http request to the server, which is built into the game engine, with some kind of command. This command is processed by the game code. Usually this is some kind of cheat, it can be arbitrarily simple or complex. For example, “give me the coordinates of the center of the button with the specified identifier.” Or “pass me the game from here to the level with the indicated number.”
- We can open the window through the cheat or find out the coordinates of the button by which this window opens, we can emulate clicking on this button, we can perform a virtual click on it.
- Finally, we can perform a “real” click on the specified coordinates as if it were done with a finger on the screen.
The latter method opens the space for the imagination of testers, who often want to test “combat” builds, where there are no cheats. Maintaining such scenarios is more difficult, but a “combat build” is a “combat” build.
It turned out to be very convenient to work with the coordinates of the center of the button: coordinates sometimes change, but button identifiers are rare. This led to another important property of the system: the ability to write one test script for all platforms and all screen resolutions.
Delivery, Reports & Traces
With delivery, everything turned out to be quite simple: we use a single shared storage for build artifacts and for storage in the distribution system. The “loading” of a build comes to invoking a pair of requests to the api of the build distribution service, essentially registering. In this way, we saved a little time on upgrading builds and money for their storage.
Remember, you talked about minimizing the resources required to fix errors found in builds?
- Reporting a problem found is a task in Asana. It is easy to control, assign to the right developer, transfer to the CI team if something went wrong in the infrastructure.
- We collect builds for every commit. We know the author of this commit, so only he will see this task. So we save time for other developers: they do not need to be distracted by problems that they have nothing to do with and help in solving which, most likely, they will not be able to.
- If you build a build from the next commit, then most likely it is still broken. There will be a comment in the task: “The build is still broken”, the author of the new commit will not see the task and will not waste time on someone else’s problem.
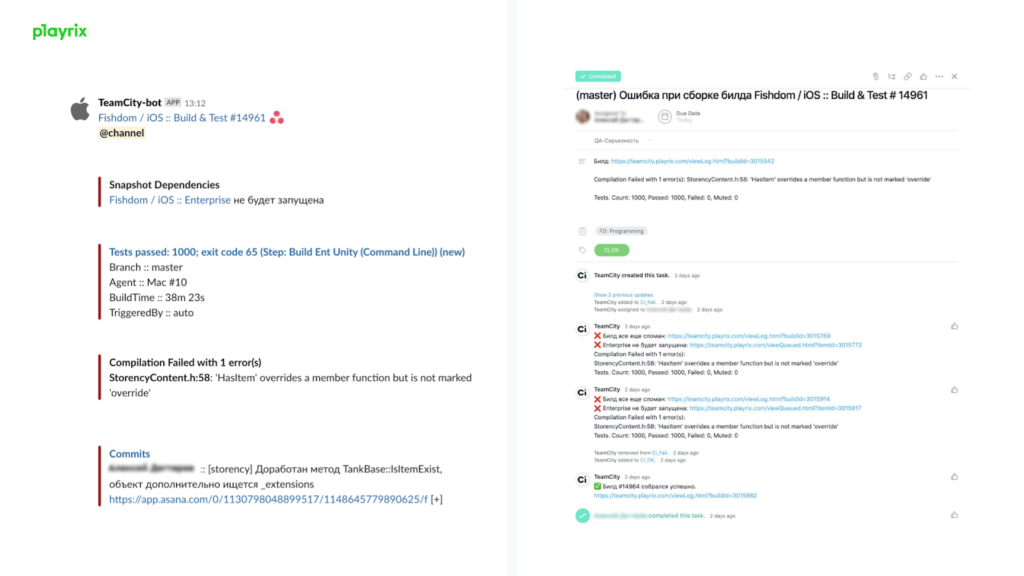
- We send reports to Slack. Necessarily – personally to the person who “broke” the build, and if the project wants – to a special channel or to any employee. Everything is as flexible as possible.
Traces are needed so that everywhere there is complete information about the build and the changes from which it was collected. In order not to look for anything, so that everything was at hand and there was no need to spend time searching for details that are often necessary when researching a problem.
- The report contains a link to the build, to the build log, the text of the compilation error found, and the names of the flipped tests. Often a programmer, having received a report task, can immediately correct the error: the file name, line and error text are in the report.
- The message in Slack contains all the same + a link to a task in Asana.
- In Teamcity, a link to a task. Build engineer can immediately go into the task, in one click, you do not need to look for anything.
- In github – status with a link to the build, in the comment to the commit – a link to the task for which this build was made. In the task – a comment with a link to the commit.
- In the build distribution service: link to the build, link to the commit.
There is nothing to remember, but you understood the idea: links to everything, everywhere. This greatly speeds up the study of any incomprehensible situation.
Farm
We collect and test builds for all platforms. For this we need a lot of different agents. Tracking and maintaining them manually is long and difficult. All agents are prepared automatically. We use Packer and Ansible.
All logs of all agents, Teamcity, all services that are around, we save (in our case – in ELK). All services, processing some kind of build, add the number of this build to each line of logs. We can see in a single request the entire life cycle of the build from its appearance in the queue to the end of sending all reports.
We have implemented our own queue optimization mechanism. The one in Teamcity doesn’t work very well on our numbers. Speaking in numbers:
- We collect about 5,000 builds every day. This is about 500 machine hours of work.
- The three millionth build was a month ago.
- We have 50+ build servers in 10 different locations.
- 40+ mobile devices on a test bench.
- Exactly 1 Teamcity server.
CI as a Service
CI in AppSoft is a service. There are many projects, many ideas.
We optimize the time from getting the build into the queue until the end of its execution, because that’s exactly what “build time” is considered by the user of the service, the developer. This allows us to search and find a balance between the build time and the time it spent in the queue. It seems logical that with the growth of the company and the number of projects, the build farm that collects these projects will also grow. But thanks to optimizations, the farm’s growth rate is far behind the company’s growth rate.
Any optimization begins with monitoring and a methodical collection of statistics. We collect a lot of statistics and we know absolutely everything about our builds. But in addition to the volume of the build farm, there is also a team that supports the CI system and makes it so that no one needs to think about where the builds come from.
Process optimization in this team is also an interesting and entertaining process. For example, we write tests for setting configurations of builds, because there are many of these configurations, without similar tests it is not easy to find all the places that need to be edited. For almost any changes, we first write a test, and then we make them, i.e., in fact, we have TDD. There are many processes related to duty, incident management, scheduling the flow of incoming tasks.
Developers should focus on creating great and successful games without worrying about where the builds come from. For this, AppSoft has a CI. There must be a goal that you want to achieve with Continuous Integration, a problem that needs to be solved. It is important not to come up with a problem, namely to find it. And when you find it, remember our experience and do better.
{kind=link}