Layer 7 DDoS attacks – protecting sites
Layer 7 DDoS attacks (application layer) are the easiest way to disable a website and harm your business. Unlike attacks at other tiers, where a powerful stream of network traffic must be set up to fail a site, attacks at tier 7 can proceed without exceeding the normal level of network traffic. How this happens, and how you can protect yourself from it, we will consider in this article.
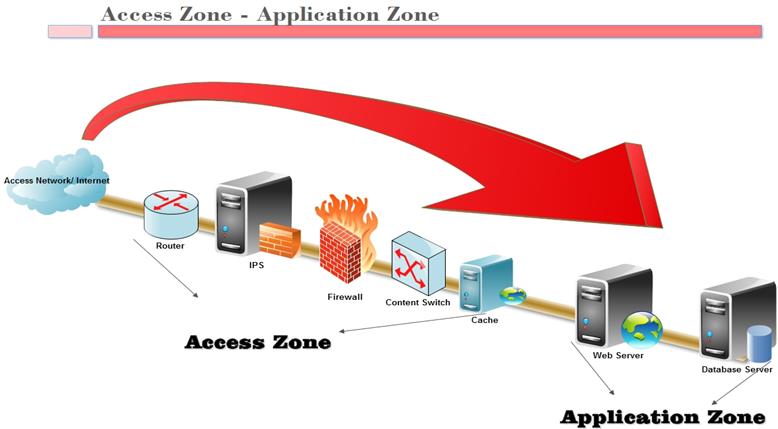
Layer 7 attacks on sites include attacks on the webserver layer (nginx, apache, etc.) and attacks on the application server layer (php-fpm, nodejs, etc.), which is usually located behind the proxy server (nginx, apache, etc.). From a network protocol perspective, both are application-layer attacks. But we, from a practical point of view, need to separate these two cases. The webserver (nginx, apache, etc.), as a rule, independently provides static files (images, styles, scripts), and proxies requests for dynamic content to the application server (php-fpm, nodejs, etc.). It is these requests that become targets for attacks, since, unlike static requests, application servers when generating dynamic content require several orders of magnitude more limited system resources, which is what attackers use.
As trite as it sounds, in order to defend against an attack, it must first be identified. In fact, not only DDoS attacks can lead to site failure, but also other reasons associated with mistakes by developers and system administrators. For the convenience of analysis, you need to add the $request_time parameter to the nginx log format (sorry, I don’t have an option with apache), and log requests to the application server in a separate file:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
log_format timed '$remote_addr - $remote_user [$time_local] ' '$host:$server_port "$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent" ($request_time s.)'; location /api/ { proxy_pass http://127.0.0.1:3000; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-NginX-Proxy true; access_log /var/log/ngunx/application_access.log timed; } |
Having received logs to the application server in a separate file (without statics logs) and with the request time in seconds, you can quickly identify the moment when the attack starts, when the number of requests and response time begins to increase sharply.
Having identified the attack, you can proceed to the defense.
Very often, system administrators try to protect the site by limiting the number of requests from a single IP address. To do this, use:
- The limit_req_zone nginx directive
- fail2ban
- iptables
Of course, these methods should be used. However, this method of protection has been ineffective for as long as 10-15 years. There are two reasons for this:
- The traffic generated by the network of bots during an attack on the 7th level may be less in volume than the traffic of an ordinary site visitor, since an ordinary site visitor has one “heavy” request to the application server (php-fpm, nodejs, etc.) there are about 100 “light” requests to download static files, which are sent by the webserver (nginx, apache, etc.). Iptables does not protect against such requests, since it can limit traffic only by quantitative indicators, and does not take into account the separation of requests into statics and dynamics.
- The second reason is the distribution of the bot network (the first letter is D in the DDoS abbreviation). The attack usually involves a network of several thousand bots. They are able to make requests less frequently than the average user. As a rule, when attacking a site, an attacker empirically calculates the limit_req_zone and fail2ban parameters. And configures the bot network so that this protection does not work. Often, system administrators begin to underestimate these parameters, thus disabling real clients, with no particular result in terms of protection from bots.
To successfully protect a site from DDoS, it is necessary that all possible means of protection are used on the server in the complex. In my previous post on this topic DDoS protection at the webserver level, there are links to materials on how to configure iptables, and what parameters of the system kernel need to be adjusted to the optimal value (meaning, first of all, the number of open files and sockets). This is a prerequisite, a necessary, but not a sufficient condition for protection from bots.
In addition, it is necessary to build protection based on detecting bots.
It is a C library and continues to be developed by a small community of authors. Probably, not all system administrators are ready to compile an unfamiliar library on a production server. If you need to make additional changes to the library’s work, then this is completely beyond the scope of an ordinary system administrator or developer. Fortunately, there are now new features: the Lua scripting language that can run on the nginx server. There are two popular builds of nginx with a built-in Lua scripting engine: openresty, which was originally inspired by Taobao, then Cloudfare, and nginx-extras, which is included with some Linux distributions, such as Ubuntu. Both options use the same libraries, so it doesn’t make much difference which one to use.
Bot protection can be based on determining the ability of the web client:
- execute JavaScript code
- make redirects
- set a cookie
Of all these methods, the execution of JavaScript code turned out to be the least promising, and we abandoned it, since the JavaScript code is not executed if the content is loaded with background (ajax) requests, and reloading the page using JavaScript distorts the statistics of transitions to the site (since the title Referer). Thus, there are redirects that set cookies, the values of which are subject to logic that cannot be reproduced on the client, and do not allow clients to enter the site without these cookies.
We are based on the leeyiw / ngx_lua_anticc library, which is currently not being developed, and continued improvements in the apapacy / ngx_lua_anticc fork, since the work of the original library did not suit everything.
For the operation of the query counters in the library, memory tables are used, which support the incr methods, convenient for increasing the counter values, and setting values with TTL. For example, the following code snippet increments the count of requests from a single IP address if the client does not have a cookie with a specific name set. If the counter has not yet been initialized, it is initialized to 1 with a TTL of 60 seconds. After exceeding the number of requests 256 (in 60 seconds), the client is not allowed to the site:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
local anticc = ngx.shared.nla_anticc local remote_id = ngx.var.remote_addr if not cookies[config.cookie_name] then local count, err = anticc:incr(remote_id, 1) if not count then anticc:set(remote_id, 1, 60) count = 1 end if count >= 256 then if count == 256 then ngx.log(ngx.WARN, "client banned by remote address") end ngx.exit(444) return end end |
Not all bots are harmful. For example, you need to skip search bots and bots of payment systems that report changes in payment statuses to the site. It’s good if you can create a list of all IP addresses from which such requests can come. In this case, you can create a “white” list:
|
1 2 3 4 5 |
local whitelist = ngx.shared.nla_whitelist in_whitelist = whitelist:get(ngx.var.remote_addr) if in_whitelist then return end |
But this is not always possible. One of the problems is the uncertainty with the addresses of the Google bots. Skipping all bots that spoof Google bots is tantamount to removing protection from the site. Therefore, we will use the resty.exec module to execute the host command:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
local exec = require 'resty.exec' if ngx.re.find(headers["User-Agent"],config.google_bots , "ioj") then local prog = exec.new('/tmp/exec.sock') prog.argv = { 'host', ngx.var.remote_addr } local res, err = prog() if res and ngx.re.find(res.stdout, "google") then ngx.log(ngx.WARN, "ip " .. ngx.var.remote_addr .. " from " .. res.stdout .. " added to whitelist") whitelist:add(ngx.var.remote_addr, true) return end if res then ngx.log(ngx.WARN, "ip " .. ngx.var.remote_addr .. " from " .. res.stdout .. "not added to whitelist") else ngx.log(ngx.WARN, "lua-resty-exec error: " .. err) end end |
Experience shows that such a protection strategy allows you to protect a site from a certain class of attacks, which are often used for unfair competition.
Understanding the mechanisms of attacks and methods of protection helps to save a lot of time on unsuccessful attempts to defend against fail2ban, and when using third-party protection (for example from Cloudfare), choose the protection parameters more deliberately.

{kind=link}