Role of Kubernetes
What if we
use Kubernetes? To begin with, this technology allows you to deploy a large
number of microservices to different machines, manage them, do autoscaling,
etc. However, there are many applications that allow you to control
orchestration, for example, Puppet, CF engine, SaltStack, and others.
Kubernetes itself is certainly good, but it can add significant overhead, which
not every project is ready to live with.
My favorite
tool is Ansible, combined with Terraform where you need it. Ansible is a fairly
simple declarative lightweight tool. It does not require the installation of
special agents and has the understandable syntax of configuration files. If you
are familiar with Docker compose, you will immediately see overlapping
sections. And if you use Ansible, there is no need to pre-re-reserve – you can
deploy systems using more classical means.
It is clear
that, these are different technologies, but there are some set of tasks in
which they are interchangeable. And a conscientious approach to design requires
an analysis of which technology is more suitable for the system being
developed. And how it will be better to match it in a few years.
If the
number of different services on your system is small and their configuration is
relatively simple, for example, you only have one jar file, and you don’t see
any sudden, explosive growth in complexity, you can probably get by with
classic deployment mechanisms.
This raises
the question, “wait, how is one jar file?”. The system should consist of as
many atomic microservices as possible! Let’s see how and what the system should
do with microservices.
Microservices
First of
all, microservices allow achieving greater flexibility and scalability, and
allow flexible versioning of individual parts of the system. Suppose we have
some kind of application that has been in production for many years.
Functionality is growing, but we cannot endlessly develop it in an extensive
way. For example.
We have an
application in Spring Boot 1 and Java 8. A wonderful, stable combination. But
the year is 2019, and whether we like it or not, we need to move towards Spring
Boot 2 and Java 12. Even the relatively simple transition of a large system to
the new version of Spring Boot can be very laborious, but about jumping from
Java 8 to Java 12 I don’t want even to talk. It means, in theory everything is
simple: we migrate, correct the problems that have arisen, we test everything
and run it in production. In practice, this can mean several months of work
that does not bring new functionality to the business. A little move to Java
12, as you know, also does not work. Here microservice architecture can help
us.
We can
allocate some compact group of functions of our application into a separate
service, migrate this group of functions to a new technical stack and roll it
into production in a relatively short time. Repeat the process piece by piece
until the old technologies are completely exhausted.
Microservices
also provide fault isolation when a single dropped component does not destroy
the entire system.
Microservices
allow us to have a flexible technical stack, and not to write everything
monolithically in one language and one version, and if necessary use a
different technical stack for individual components. Of course, it is better
when you use a uniform technical stack, but this is not always possible, and in
this case microservices can help out.
Microservices
also allow a technical way to solve a number of managerial problems. For
example, when your large team consists of separate groups working in different
companies (sitting in different time zones and speaking different languages).
Microservices help isolate this organizational diversity by components that
will be developed separately. The problems of one part of the team will remain
inside one service, and not spread throughout the application.
But
microservices are not the only way to solve these problems. A few decades ago,
for half of them, people came up with classes, and a little later – components
and the Inversion of Control pattern.
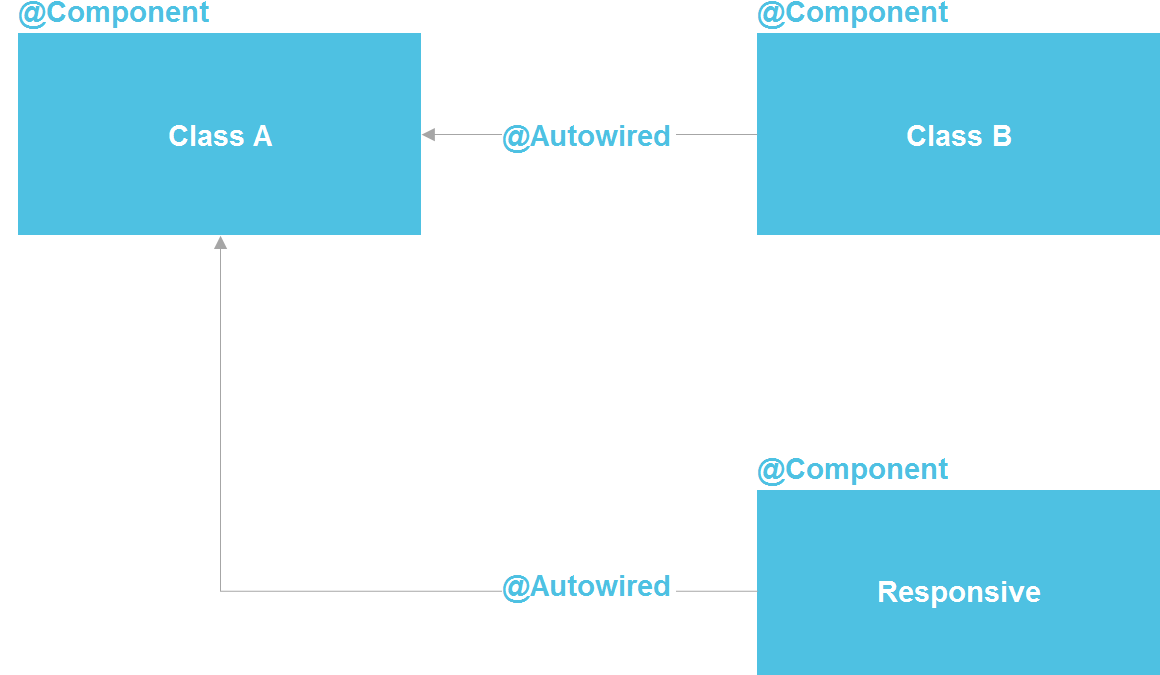
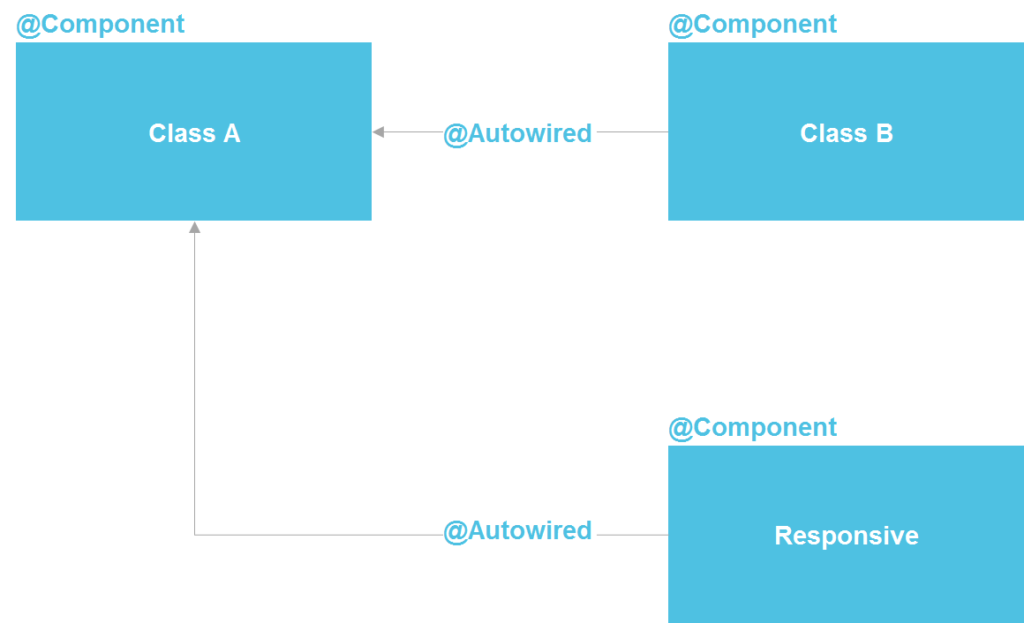
If we look
at Spring, we see that in fact it is a microservice architecture inside a Java
process. We can declare a component, which, in essence, is a service. We have
the ability to do a lookup through @Autowired, there are tools for managing the
component life cycle and the ability to separately configure components from a
dozen different sources. In principle, we get almost everything that we have
with microservices – only inside one process, which significantly reduces
costs. A regular Java class is the same API contract that also allows you to
isolate implementation details.
Strictly
speaking, in the Java world, microservices are most similar to OSGi – there we
have an almost exact copy of everything that is in microservices, except,
besides the possibility of using different programming languages and code
execution on different servers. But even staying within the capabilities of
Java classes, we have a powerful enough tool to solve a large number of
isolation problems.
Even in a
“managerial” scenario with team isolation, we can create a separate repository
that contains a separate Java module with a clear external contract and a set
of tests. This will significantly reduce the ability of one team to complicate
the life of another team.
I have
repeatedly heard that it is impossible to isolate implementation details
without microservices. But I can answer that the entire software industry is
just about isolating the implementation. For this, a subroutine was first
invented (in the 50s of the last century), then functions, procedures, classes,
and later microservices. But the fact that microservices in this series
appeared last does not make them the highest point of development and does not
oblige us to always resort to their help.
When using
microservices, one must also take into account that calls between them take
some time. This is often unimportant, but I have seen a case where the customer
needed to fit the system response time of 3 seconds. It was a contractual
obligation to connect to a third-party system. The chain of calls passed
through several dozen atomic microservices, and the overhead of making HTTP calls
did not make it possible to go in 3 seconds. In general, you need to understand
that any division of monolithic code into a number of services inevitably
affects the overall performance of the system. Just because data cannot be
teleported between processes and servers “for free.”

{kind=link}
{kind=link}
{kind=link}