
Do you always need Docker, microservices and reactive programming?
In AppSoft, I work in two ways. In the first, I help people to repair systems that are broken in one way or another and for a variety of reasons. In the second, I help to design new systems so that they are not broken in the future, or, more realistic, to break them is more difficult.
If you are not doing something fundamentally new, for example, the world’s first Internet search engine or artificial intelligence to control the launch of nuclear missiles, creating a good system design is quite simple. It is enough to take into account all the requirements, look at the design of similar systems and do about the same, without making any serious mistakes. It sounds like an oversimplification of the issue, but let’s recall that now is the year 2019, and there are “standard recipes” for system design for almost everything. A business can give complex technical tasks – process a million heterogeneous PDF files and take out expense tables from them – but the system architecture is rarely very original. The main thing here is not to make a mistake in determining which system we are building, and not to miss the choice of technologies.
What is the difficulty of choosing a technical stack? Adding any technology to the project makes it more difficult and brings some limitations. Accordingly, adding a new tool (framework, library) should only be done when this tool is more useful than harmful. In conversations with team members about adding libraries and frameworks, I often jokingly use the following trick: “If you want to add a new dependency to the project, you put a box of beer for the team. If you think that this dependence doesn’t worth a box of beer, do not add it. ”
Suppose we create a certain application, let’s say, in Java and add the TimeMagus library to the project for manipulating dates (an example is fictitious). The library is excellent, it provides us with many features that are not available in the standard class library. How can such a decision be harmful? Let’s look at the possible scenarios:
- Not all developers know a non-standard library, the entry threshold for new developers will be higher. The chance increases that a new developer will make a mistake when manipulating a date using an unknown library.
- The size of the distribution is increasing. When the size of the average application on Spring Boot can easily grow to 100 MB, this is really important. I saw cases when, for one method, a 30 MB library was pulled into the distribution kit. They justified it this way: “I used this library in a previous project, and there is a convenient method there.”
- Depending on the library, the start time may increase.
- The library developer can abandon his project, then the library will begin to conflict with the new version of Java, or a bug will be detected in it (caused for example by changing time zones), and no patch will be released.
- The library license at some point will conflict with the license of your product (do you check the licenses for all the products that you use?).
- Jar hell – the TimeMagus library needs the latest version of the SuperCollections library, then after a few months you need to connect the library for integration with a third-party API, which does not work with the latest version of SuperCollections, and only works with version 2.x. You can’t connect an API, there is no other library for working with this API.
From the other side, the standard library provides us with convenient tools for manipulating dates, and if you don’t need, for example, to maintain some kind of exotic calendar or calculate the number of days from today to “the second day of the third new moon in the previous year of the soaring eagle”, it may be worth refrain from using a third-party library. Even if it’s completely wonderful and on a project scale, it will save you around 50 lines of code.
The considered example is quite simple, and I think it’s easy to make a decision. But there are a number of technologies that are widespread and their use is obvious, which makes the choice more difficult – they really provide serious advantages to the developer. But this should not always be a reason to drag them into your project. Let’s look at some of them.
Docker
Before appearing of this really cool technology, when deploying systems, a lot of unpleasant and complex issues arose related to version conflict and obscure dependencies. Docker allows you to pack a snapshot of the system status, roll it into production and run it there. This allows the mentioned conflicts to be avoided, which, of course, is great.
Previously, this was done in some monstrous way, and some tasks were not solved at all. For example, you have a PHP application that uses the ImageMagick library for working with images, your application also needs specific php.ini settings, and the application itself is hosted using Apache httpd. But there is a problem: some regular routines are implemented by running Python scripts from cron, and the library used by these scripts conflicts with the library versions used in your application. Docker allows you to pack your entire application, along with settings, libraries, and an HTTP server, into one container that serves requests on port 80, and routines into another container. All together will work perfectly, and you can forget about the conflict of libraries.
Should I use Docker to pack each application? My opinion: no, not worth it. The picture shows a typical composition of a dockerized application deployed in AWS. Rectangles here indicate the insulation layers that we have.
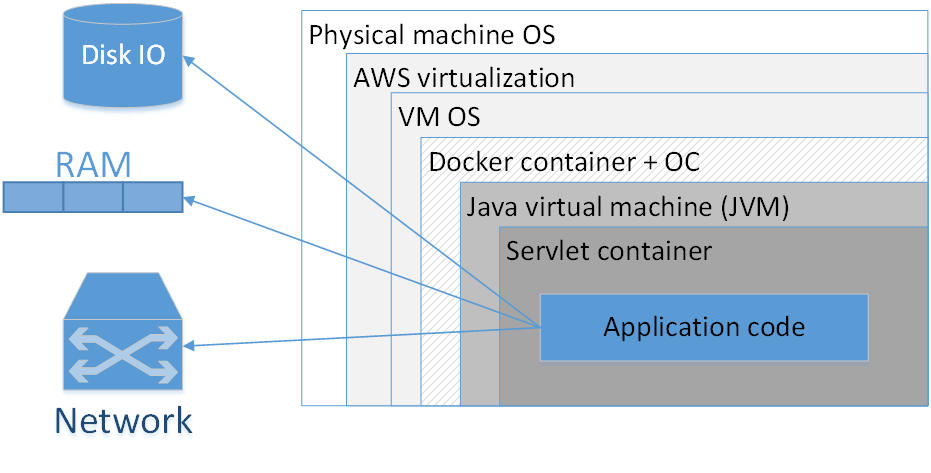
The largest rectangle is the physical machine. Next is the operating system of the physical machine. Then – the Amazonian virtualizer, then the virtual machine OS, then the docker container, followed by the container OS, JVM, then the Servlet container (if it is a web application), and your application code is already inside it. That is, we already see quite a few layers of isolation.
The situation will look even worse if we look at the acronym JVM. The JVM is, oddly enough, the Java Virtual Machine, what mwans, in fact, we always have at least one virtual machine in Java. Adding here an additional Docker container, firstly, often does not give such a noticeable advantage, because the JVM itself pretty well isolates us from the external environment, and secondly, it is not without cost.
I took figures from an IBM study, if not mistaken, two years ago. Briefly, if we are talking about disk operations, processor usage or memory access, Docker almost does not add an overhead (literally a fraction of a percent), but if it comes to network latency, the delays are quite noticeable. They are not gigantic, but depending on what kind of application you have, they may surprise you unpleasantly.
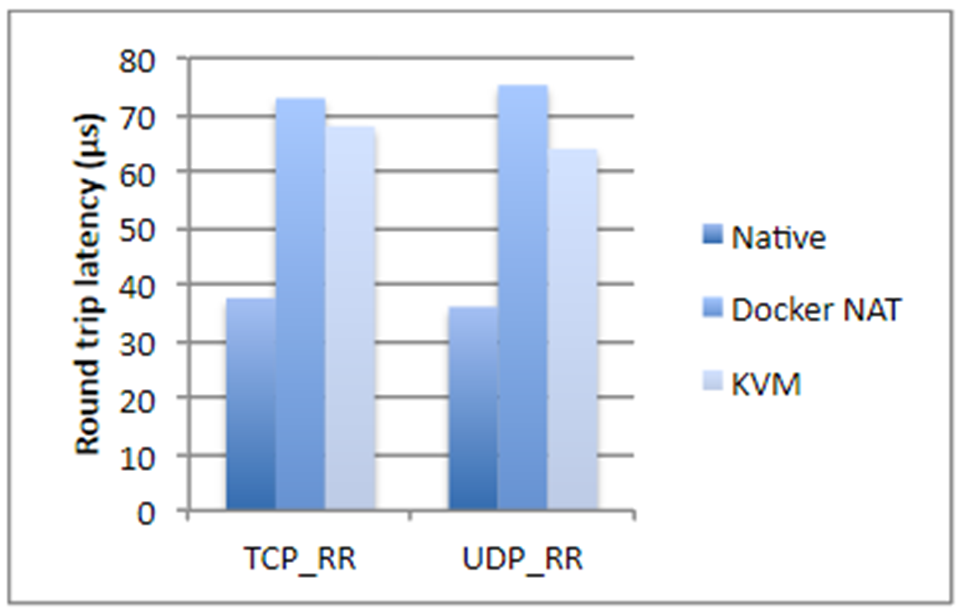
Plus, Docker needs additional disk storage, takes up part of the memory, adds start up time. All three points are uncritical for most systems – usually there is a lot of disk space and memory. Launch time, as a rule, is also not a critical problem, the main thing is that the application starts. But still there are situations when memory may run out, and the total start-up time of a system consisting of twenty dependent services is already quite large. In addition, this affects the cost of hosting. And if you are engaged in any high-frequency trading, Docker absolutely does not suit you. In the general case, it is better not to docker any application that is sensitive to network delays up to 250–500 ms.
Also, with the docker, the analysis of problems in network protocols is noticeably complicated, not only delays grow, but all timings become different.
When is Docker really needed?
When we have different versions of the JRE, and it would be nice to take the JRE along. There are times when you need to run a certain version of Java (not “the latest Java 8”, but something more specific). In this case, it is good to pack the JRE with the application and run as a container. In principle, it is clear that different versions of Java can be put on the target system due to JAVA_HOME, etc. But Docker in this sense is much more convenient, because you know the exact version of the JRE, everything is packed together and with another JRE the application will not even start by accident.
Docker is also necessary if you have dependencies on some binary libraries, for example, for image processing. In this case, it might be a good idea to pack all the necessary libraries with the Java application itself.
The following case refers to a system that is a complex composite of various services written in various languages. You have a piece on Node.js, a part in Java, a library in Go, and, in addition, some Machine Learning in Python. This whole zoo must be carefully and carefully tuned in order to teach its elements to see each other. Dependencies, paths, IP addresses – all this needs to be descripted and carefully raised in production. Of course, in this case, Docker will help you a lot. Moreover, doing it without its help is simply hard.
Docker can provide some convenience when you need to specify many different parameters on the command line to start the application. From the other side, bash scripts do this very well, often from a single line. Decide for yourself which is better.
The last thing that comes to mind at once is the situation when you use, for example, Kubernetes, and you need to do orchestration of the system, raise a certain number of different microservices that automatically scale according to certain rules.
In all other cases, Spring Boot is enough to pack everything into a single jar file. And, in principle, the springboot jar is a good metaphor for the Docker container. This, of course, is not the same thing, but in terms of ease of deployment, they are really similar.
{kind=link}
{kind=link}
{kind=link}