Microservices and reactive programming
When are microservices needed?
In what cases does a monolithic application really need to be divided into several microservices? First, when there is an unbalanced use of resources in functional areas.
For example, we have a group of API calls that perform computations that require a lot of processor time. And there is a group of API calls that are executed very quickly, but require a 64 GB data structure to be stored in memory. For the first group, we need a group of machines with a total of 32 processors, for the second one one machine is enough (OK, let there be two machines for fault tolerance) with 64 GB of memory. If we have a monolithic application, then we will need 64 GB of memory on each machine, which increases the cost of them. If these functions are divided into two separate services, we can save resources by optimizing the server for a specific function. The server configuration may look like this:

Microservices are needed and if we need to seriously scale some narrow functional area. For example, a hundred API methods are called 10 times per second, and, let‘s say, four API methods are called 10 thousand times per second. Scaling up the entire system is often not necessary, of course, we can multiply all 100 methods onto many servers, but this is usually noticeably more expensive and more complicated than scaling a narrow group of methods. We can separate these four calls into a separate service and scale it only to a large number of servers.
It is also clear that we may need a microservice if we have written a separate functional area, for example, in Python. Because some library (like for Machine Learning) turned out to be available only in Python, and we want to move it into a separate service. It also makes sense to make a microservice if some part of the system can fail. It’s good, of course, to write code so that there are no crashes in general, but the reasons may be external. And no one is safe from their own mistakes. In this case, the bug can be isolated inside a separate process.
If your application does not have any of the above and is not expected in the foreseeable future, most likely, a monolithic application will suit you best. The only thing – I recommend writing it so that functional areas that are not related to each other do not depend on each other in the code. So that, if necessary, functional areas that are not interconnected can be separated from each other. However, this is always a good recommendation, following which increases internal consistency and teaches you to carefully formulate module contracts.
Reactive architecture and reactive programming
A reactive approach is a relatively new thing. The moment of its appearance can be considered the year 2014, when The Reactive Manifesto was published. Two years after the publication of the manifesto, it was well-known to everyone. This is a truly revolutionary approach to system design. Its individual elements were used decades ago, but all the principles of the reactive approach together, as set out in the manifest, allowed the industry to take a serious step forward in designing more reliable and higher-performance systems.
Unfortunately, a reactive design approach is often confused with reactive programming. When I asked why I should use the reactive library in the project, I heard the answer: “This is a reactive approach, didn’t you read the reactive manifesto !?” I read and signed the manifesto, but, reactive programming does not have a direct relationship to reactive programming, except that in the names of both there is the word “reactive”. You can easily make a reactive system using a 100% traditional set of tools, and create a completely non-reactive system using the latest developments in functional programming.
A reactive approach to system design is a fairly general principle that applies to so many systems – it definitely deserves a separate article. Here I would like to talk about the applicability of reactive programming.
What is the essence of reactive programming? First, let’s see how a regular non-reactive program works.
A thread executes some code that does some kind of calculation. Then comes the need to perform some kind of I / O operation, for example, an HTTP request. The code sends a packet over the network, and the thread is blocked waiting for a response. A context switch occurs, and another thread starts executing on the processor. When a response arrives over the network, the context switches again, and the first thread continues execution, processing the response.
How will the same piece of code work in a reactive style? The thread performs the calculations, sends an HTTP request, and instead of blocking and processing the synchronously upon receipt of the result, it describes the code (leaves a callback) that must be executed as a reaction to the result. After that, the thread continues to work, doing some other calculations (maybe just processing the results of other HTTP requests) without switching the context.
The main advantage here is the lack of context switching. Depending on the system architecture, this operation may take several thousand cycles. What means, for a processor with a clock speed of 3 Ghz, context switching will take at least microseconds, in fact, due to invalidation of the cache, etc. rather, several tens of microseconds. Practically speaking, for an average Java application that processes many short HTTP requests, the performance gain can be 5-10%. We can not say that it is decisively a lot, but, if you rent 100 servers at 50 $ / month each – you can save $ 500 per month on hosting. Not super, but enough to drink beer several times.
So, go ahead for a beer? Let’s look at the situation in detail.
A program in the classical imperative style is much easier to read, understand and, as a result, debug and modify. In principle, a well-written reactive program also looks quite understandable, the problem is that writing a good, understandable not only to the author of the code here and now, but also to another person in a year and a half, the reactive program is much more complicated. But this is a rather weak argument, I have no doubt that for readers of the article to write a simple and understandable reactive code is not a problem. Let’s look at other aspects of reactive programming.
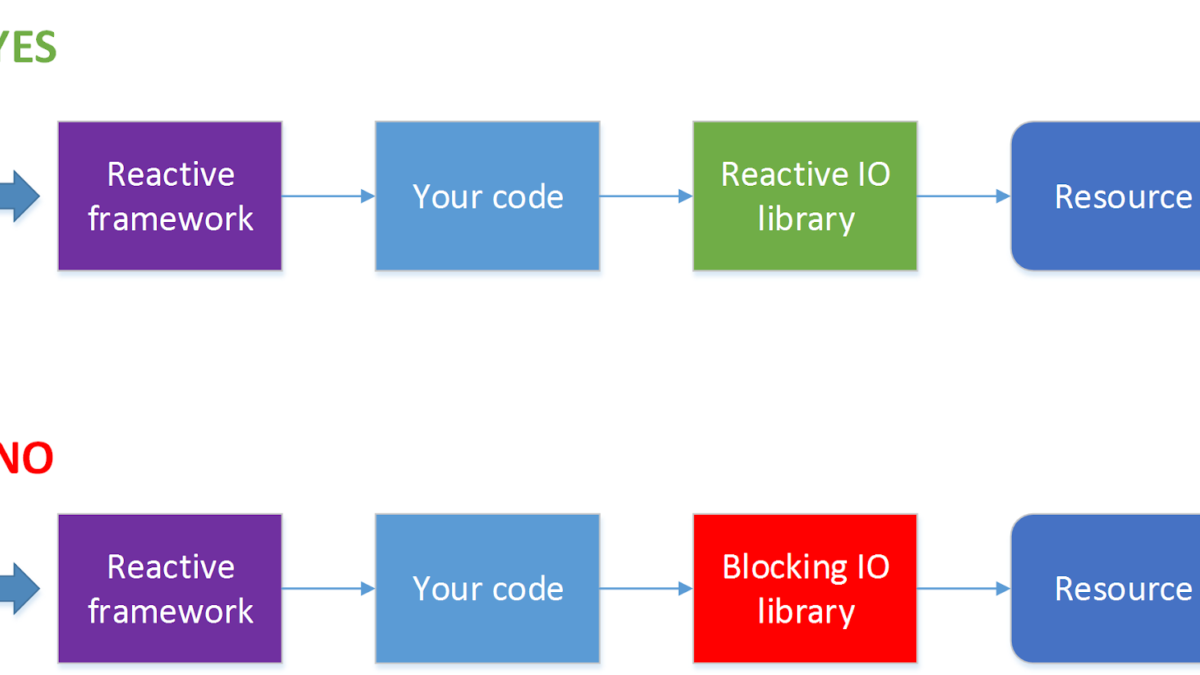
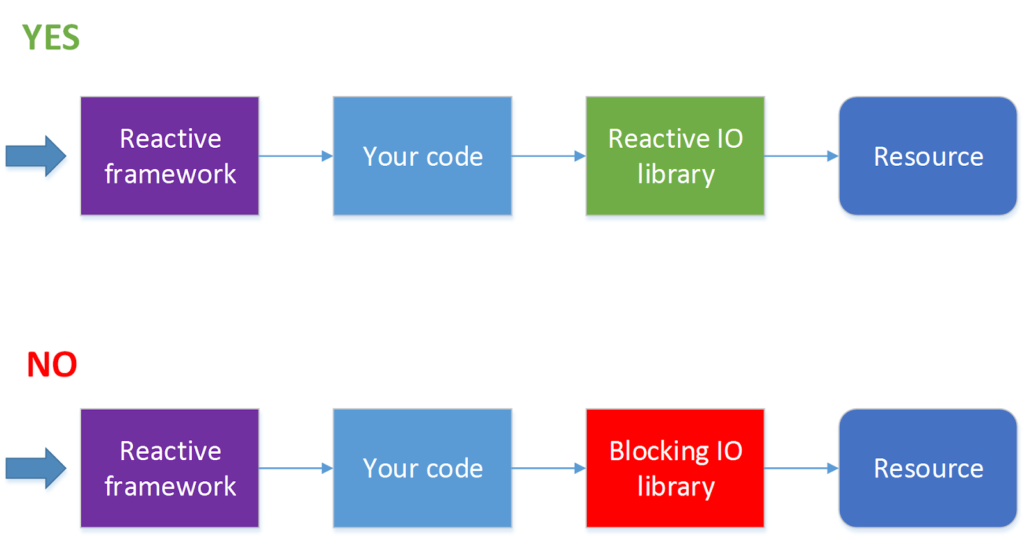
Not all I / O operations support non-blocking calls. For example, JDBC does not currently support . Since now 90% of all applications go to databases, using a reactive framework automatically turns from a virtue into a disadvantage. For such a situation, there is a solution – to process HTTP calls in one thread pool, and database calls in another thread pool. But at the same time, the process is much more complicated, and without urgent need I would not do that.
When to use reactive framework?
It is worth using a framework that allows for reactive processing of requests when you have a lot of requests (several hundred seconds or more) and at the same time a very small number of processor cycles are spent on processing each of them. The simplest example is proxying requests or balancing requests between services or some kind of fairly lightweight processing of responses received from another service. Where we mean something by a service, a request to which can be sent asynchronously, for example, via HTTP.
If, however, when processing requests, you need to block the thread while waiting for a response, or request processing takes a relatively long time, for example, you need to convert a picture from one format to another, writing a program in a reactive style may not be worth it.
Also, do not need to write complex multi-step data processing algorithms in a reactive style. For example, the task “to find files with specific properties in the directory and all its subdirectories, convert their contents and send them to another service” can be implemented as a set of asynchronous calls, but, depending on the details of the task, such an implementation may look completely opaque and not give noticeable advantages over the classic sequential algorithm. If this operation should be launched once a day, and there is not much difference, it will take 10 or 11 minutes, maybe you should choose not the best, but a simpler implementation.
Conclusion
In conclusion, I want to say that any technology is always designed to solve specific problems. And if, when designing a system in the foreseeable future, these tasks are not important for you, most likely you do not need this technology here and now, no matter how beautiful it may be.


{kind=link}
{kind=link}
{kind=link}