Cleaning of Jira. Step-by-step guide
Step 1. We don’t configure anything
Do not change workflow, statuses, resolutions. Although it’s unusual to deal with unusual statuses, but this is data in which people invested some sense.
Step 2. We remove old projects
Report in the format (Project, Last date of the last change in the task status).
Projects for which there were no movements are candidates for transfer to the archive.
If the person responsible for the project is still working, he will say its status, if not, the quest for finding the ends begins.
The tasks of archival projects are transferred to the final status with won’t fix. There are frozen projects. The status of such tasks moves into frozen.
Step 3. We remove old tasks
Report on unclosed tasks with the last change of status less than X (two years more than enough. But usually, if a task hangs for 90 days – it “goes bad”) days, grouped by assignee.
Step 4. Remove unnecessary task types
A report of the distribution of unclosed tasks by task type to drop out unnecessary types.
Step 5. We analyze the tasks of the people, who worked before
We single out tasks with fired performers.
It is especially interesting to look at the tasks of laid-off employees in the context of their superiors. The head of the employee allowed the “drain” of the associated capital for the time spent on the task and did not organize the completion of the task.
We enter in the regulation on dismissal the obligation to close irrelevant tasks.
Step 6. Search and parse the largest heap
Report on statuses of unclosed tasks. We identify in which status the most tasks.
If the status is a task in the work, then we build a report on the distribution of tasks in this status by performers. We single out tasks without an assigned executor, we look at tasks by “live” executors. On some artist 2000 tasks have accumulated.
Step 7. We standardize statuses, resolutions, life cycles
An opportunity to look equally at any project. We meet and break the resistance of the PM. Alas, people do not like to think about their interchangeability, a typical argument: “I am unique in managing a project, I need a unique life cycle.”
Step 8. We are looking for the most problematic projects. We look at the reports of combustion
There can be two types of Jira – projects
- Projects with a known scope of tasks (this happens), where combustion reports are applicable. Sometimes it happens.
- Processes: Processing of Continuing Tasks
Projects
If the task pool is started, then we look at the completion forecast and take actions if the forecast is not comforting.
Processes
We look at the solved problems against incoming tasks.
Divided tasks are separetad into external and internal (training, refactoring, etc.), we display only external ones on the chart.
How to read charts
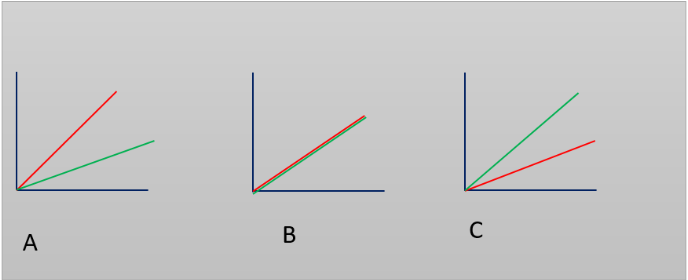
There are three conditional graphs:
The reality of IT is that the labor involved in releasing tasks has a significant statistical scatter.
As a result, to ensure the necessary SLA for support, resources must be planned with a margin, otherwise this will lead to the accumulation of tasks in the incoming task buffers, which will make the deadlines inadmissible. People will not always be loaded with incoming tasks, doing training or other non-core work during breaks.
In the process of product development, we try to prevent developers from downtime to ensure maximum development speed = making money. To do this, you must always have a supply of tasks in the backlog, which means that part of the task will most often not be done, and since tasks are gradually losing relevance, this means that tasks will never be done.
Option A
It’s normal if this is an implementation of features. More features enter the input than the team can take in attention.
If this is support (administration and bug fixing), then the situation is bad. The more errors, the slower their correction. The slower the correction, the more errors accumulate.
Option B
If a team does exactly as many tasks as it comes to the backlog, then this means that
- either the backlog is maintained in another project / place and, as a result, you do not see future income in the reports and cannot make a decision based on reports on the importance of increasing the size of the team,
- or people invent tasks for themselves at the time of inactivity (on sensations and intuition, without custdev, market analysis, etc.); how many such tasks are unclear and this is alarming (what if there are already 90% of them),
- or the reports are faked.
Option C
OK if it’s support. The team should have downtime so that it can quickly and efficiently solve problems and tasks.
If this is an implementation of features, then the situation is most often not normal. Once backlog of tasks was accumulated, which understands faster than new ones. Why could this be?
- For example, the team has been dramatically increased and it is analyzing the debt, but at the same time, the business needs are no longer growing. The business does not respond (did not have time to react) to the growth of opportunities or worse, the product has taken its place and stopped growing.
- Or the product stagnates and does not require development.
- Or marketing has stopped creating new opportunities.
Stage access security step
We catch tasks with links on the Internet to Google Docs. All documents must be inside the perimeter, we set the task of transferring materials inward
Analyst Control Step
Stages are made where?
Option A. Right in the Jira.
Option B. In the employee’s personal Google Docs.
Correct option: A change in functionality should most often be accompanied by a change in the technical and working documentation in Confluence. How to control it?
We link the statement page to the task in Jira (just insert the link, this will automatically lead to the creation of bidirectional links).
We build a report on page changes in confluence and summarize it on analytics with Jira reports on improvements with labor costs. All improvements with significant labor costs should correlate with changes to the articles.

{kind=link}
{kind=link}
{kind=link}
{kind=link}