
Domain Driven Design Tools
The blue whale is a great example of how the design of a complex project went wrong. The whale looks like a fish, but it is a mammal: it feeds the babies with milk, it has hair, and the bones of the forearm and hands with fingers are still preserved in the fins. It lives in the oceans, but cannot breathe underwater, so it regularly rises to the surface to swallow air, even when it sleeps. The whale is the largest animal in the world, with the length of a nine-floor house, and weighing as many as 75 Volkswagen Touareg cars, but not a predator and feeds on plankton.
When the developers worked on the whale, they did not begin to write everything from scratch, but used the experience from old projects. It seems to be added together from incompatible parts of the code that were not tested, and all the design came down to choosing a framework and urgent “cycling” already in production. As a result, the project turned out to be beautiful in appearance, but with pieces of dense legacy and bugs inside.
To create projects that help businesses earn money, rather than looking like a marine animal that cannot breathe underwater, there is DDD. This is an approach that focuses not on tools or code, but on the study of the subject area, individual business processes and how code or tools work for business logic.
Complexity
What is programming?
Complexity is divided into two types: introduced and natural. The introduced one extends along with programming languages, frameworks, OS, asynchrony model. This is a technical challenge that does not apply to business. Natural complexity is hidden in the product and simplifies the life of users – for this people pay money.
But we programmers are complex people and we love to add technical complexity to projects. For example, we did not bother with coding standards, did not use linters, modular design practices, and received a lot of code in projects in the style if c == 1.
How to work with such code? Read a lot of files, understand variables, conditions, and when and how it will all work. This code is hard to keep in mind – absolutely technical added complexity.
Another example of added complexity is my favorite callback hell.
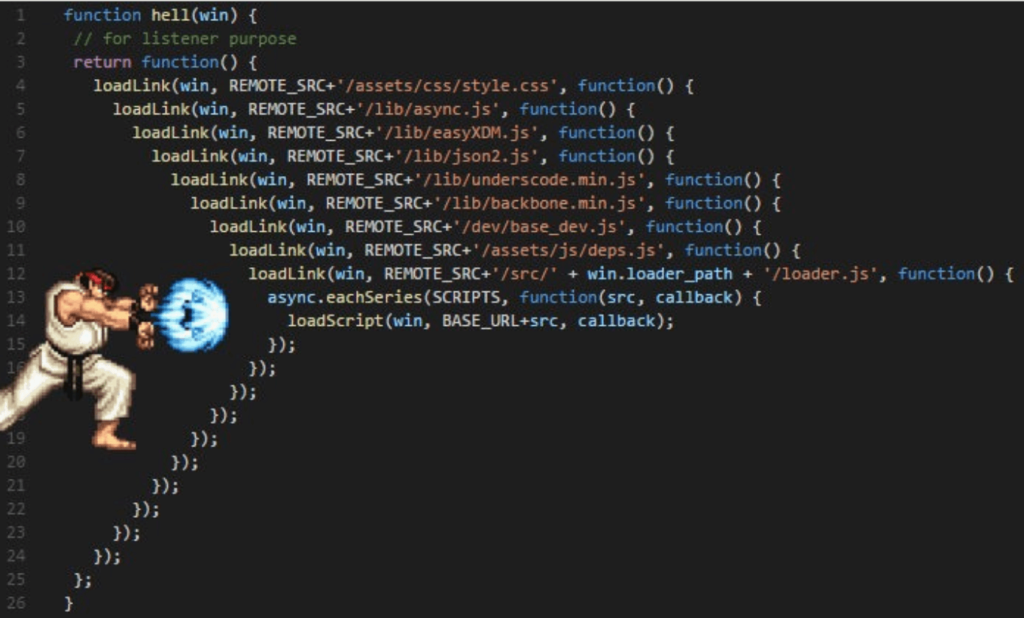
When we write in the framework of an event-driven architecture (EDA) and choose a not-so-good modern framework, we get a code in which it is not clear what happens and when. It’s hard to read such a code – this is again the added complexity.
Programmers not only adore technical difficulties, but also argue which one is better:
- AsyncIO or Gevent;
- PostgreSQL or MongoDB;
- Python or Go;
- Emacs or Vim;
- tabs or spaces;
The correct answer of a good programmer to all these questions: “It makes no difference!” Good developers do not argue over spherical horses in a vacuum, but solve business problems and work on the usefulness of the product. Some of them have long established a set of practices that reduce the complexity introduced and help you think more about the business.
One of them is Eric Evans. In 2004, he wrote the book Domain Driven Design. It “shot” and gave an impulse to think more about the business, and push the technical details to the background.
What is DDD?
First a solution to the problem, and then tools. First of all, Evans invested in the concept of DDD, that this is not a technology, but a philosophy. In philosophy, you first need to think about how to solve the problem, and only then, with the help of which tools.
Work on models with subject matter experts and software developers. We must communicate with people from business: look for a common language, build a model of the world within which our product will work and solve problems.
Write software that explicitly expresses models. The most important difference between DDD and simple collaboration in a team is that we should write software in the same style as we speak with domain experts. All terminology, approaches to discussion and decision-making should be stored in the source code so that even a non-technical person can understand what is happening there.
Speak the same language with business. DDD is a philosophy about how to speak the same language with business experts within a specific field and apply terminology to this field. We have a common language or dialect within the bounds of the context that we consider to be true. We create boundaries around architectural solutions.
First, the technical part, then – DDD. The sculptor who carves the statue from stone does not read the manual on how to hold a hammer and chisel – he already knows how to work with them. To bring DDD into your project, master the technical part: learn Django to the end, read the tutorial and stop arguing about whether to use PostgreSQL or MongoDB.
Most design templates and patterns are technical noise. Most of the patterns that we know and use are technical. They say how to reuse code, how to structure it, but they don’t say how to use it for users, businesses, and model the outside world. Therefore, factories or abstract classes are loosely bound to DDD.
The first “blue” book came out almost 20 years ago. People tried to write in this style, walked a rake, and realized that the philosophy is good, but in practice incomprehensible. Therefore, a second book appeared – “red”, about how programmers think and write in DDD.

The red book skips the idea of how best to bring DDD into the project, how to structure the work around this approach. A new terminology appears – “Model-Driven Design”, in which our model of the outside world is put in the first place.
The only place, where technology is chosen is Smart UI. This is a layer between the outside world, the user and us.
What is a model? This is the phantom pain of any architect. Everyone thinks this is UML, but it is not.
The model reflects a real object with all the necessary properties and functions. This is a high-level toolkit for making decisions from the point of view of business cases. Methods and classes, on the other hand, are low-level tools for architectural solutions.
Dry-python
To fill the model niche, I started a dry-python project that has grown into a collection of high-level architectural library for building Model Driven Design. Each of the libraries is trying to close one circle in the architecture and does not interfere with the other. Libraries can be used separately, or together if you get a taste.
The sequence of the narrative corresponds to the chronology of the optimal addition of DDD to the project – by layers. The first layer is services, a description of business scenarios (processes) in our system. The Stories library is responsible for this layer.
Stories
Business scenarios are divided into three parts:
- specification – a description of the business process;
- state in which the business scenario may exist
- implementation of each step of the script.
These parts must not be mixed. The Stories library separates these parts and draws a clear line between them.
Lets consider the introduction of DDD and Stories as an example. For example, we have a project on Django with a mix of Django signals and obscure “thick” models. Add an empty services package to it. Using the Stories library in parts, we rewrite this hash into a clear and understandable set of scripts in our project.
DSL specification. The library allows you to write a specification and provides DSL for this. This is a way to describe user actions step by step. For example, to buy a subscription, I follow several steps: I will find an order, check the relevance of the price, check if the user can afford it. This is a high level description.
Contract. Below this class we will write a contract for the state of the business scenario. To do this, we denote the area of variables that arise in the business process, and for each variable we assign a set of validators.
As soon as someone tries to assign a variable to this area as part of the business process, a set of validators will be worked out. We will be sure that the state of the process at runtime is always working. But if not, it painfully falls and screams loudly about it.
Stage of implementation of each step. In the same subscription class, we write a set of methods whose names correspond to business steps. Each input method receives a state with which it can work, but does not have the right to modify it. The method may return some marker and report:
- that successfully worked out, and suggest placing the variables in the area (scope) for further execution;
- that it checked something and understands that further execution does not make sense.
There are more complex markers: they can confirm that the state is working, suggest deleting or changing some parts of the business process. You can also write in classes.
Launch Story. How to run Story on execution? This is a business object that works as a method: we transfer data to the input, it validates them, interprets the steps. The running Story remembers the execution history, records the state that occurred in it in the business process, and tells us who influenced this state.
Debug toolbar. If we write in Django and use the debug panel, we can see what business scenarios were processed in each request and their status.
Py.test. If we write in py.test, then for the crashed test we can see what business scripts were executed on each line and what went wrong. This is convenient – instead of picking in the code, we read the specification and understand what happened.
Sentry. Even better, when we get error 500. In a regular system, we put up with it and begin to investigate. In Sentry, a detailed report will appear on what the user did to make the mistake. It is convenient and pleasant when at 3 a.m. such information was collected for you.
ELK. Now we are actively working on a plugin that writes all this in Elasticsearch to the Kibana stack and builds competent indexes.
For example, we have a contract for the status of a business process. We know that there is, for example, relation ID of the report. Instead of archaic research of what once happened there, we write a request in Kibana. It will show all Stories that are related to a specific user. Next, we examine the state within our business processes and business scenarios. We do not write a single line of logging code, but the project is logged at the very level of abstraction at which we are interested to watch.
But I want something higher level, for example, light objects. Such objects contain competent data structures and methods that relate to business decision making, and not to working with a database, for example. Therefore, we move on to the next part of the Model-Driven architecture — entities, agregates, and value objects.
Entities, agregates and value objects
How is all this interconnected? For example, a user places a product order and we bill. What is the root of aggregation, and what is a simple object?
All that is underlined is the root of aggregation. This is what I want to work directly with: important, valuable, holistic.
Where to begin? We will create an empty package in the project, where we will put our units. Aggregates are best written with something declarative, like dataclasses or attrs.
Dataclasses. If we specify an dataclass as an aggregate, we will write an annotation on it using NewType. In the annotation we indicate an explicit reference, which is expressed in the type system. If the dataclass is just an entity structure, then save it inside the aggregate.
In the context of Stories, only aggregates can lie. Access to something embedded in them can only be obtained through public methods and high-level rules. This allows you to logically and competently build a model over which we work together with experts from the subject area. This is the same single language.
The problem immediately arises – repositories. I have a database with which I work through Django, the neighboring microservice to which I send requests, there is JSON and an instance of the Django model. To receive data and transfer it by hand, just to call or test the method beautifully? Of course not. Dry-python has a Mappers library that allows you to map high-level abstractions and domain aggregates to the places where we store them.
Mappers
We add one more package to our project – a repository in which we will store our mappers. This is how high-level business logic will be transferred to the real world.
For example, we can describe how we map a dataclass to a Django model.
Django ORM. We compare the order model with the description of Django ORM – we look at the fields.
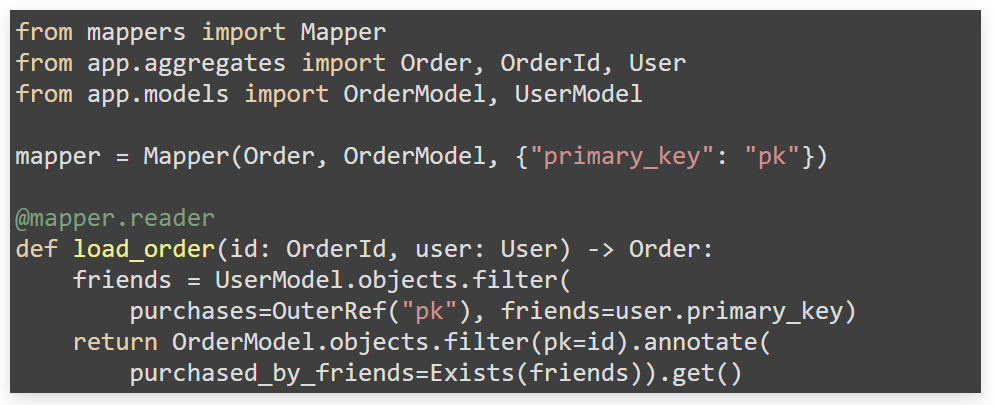
For example, we can rewrite some fields through the optional config. The following will happen: mapper during the declaration will compare how the dataclass and model are written. For example, int annotations (in Order dataclass there is a cost field with int annotation) in the Django model there is an integer field with the option nullable = “true”. Here, the dataclass will suggest adding optional to the dataclass, or removing nullable from the field.
Through Mappers, you can add functions that read or write something. Readers are functions that receive an aggregate at the input and return a reference to it. Writers do the opposite – return the units.
Swagger definitions: The same operations can be done with microservices. You can write a part of the swagger scheme on them and check how much the swagger scheme of a particular service matches your domain models. Further, the returned request from the Request library will be transparently translated into dataclass.
GraphQL queries. GraphQL and microservices: GraphQL interface type schema is perfectly validated against dataclass. You can translate specific GraphQL queries into internal data structures
Why bother with such an internal high-level data model inside an application? To illustrate the “why,” I will tell an “entertaining” story.
In one of our projects, web sockets worked through the Pusher service. We did not bother, we wrapped it in an interface so as not to call directly. This interface was tied in all the Stories and were satisfied.
But business requirements have changed. It turned out that the guarantees that Pusher provides for web sockets are not enough. For example, you need guaranteed message delivery and message history for the last 2 minutes. Therefore, we decided to move to the Ably Realtime service. It also has an interface – we will write an adapter and bind it everywhere, everything will be great. Not really.
The abstractions that Pusher uses (function arguments) fall into every business object. I had to fix about 100 Stories, and fix the formation of the user channel to which we are sending something.
Back to the tests.
Tests & mocks
How do you usually test this behavior with external services? We’re wetting something, we are watching how a third-party library is called, and that’s all – we are sure that everything is fine. But when the library changes, the argument formats change too.
You can save a week rewriting thousands of tests and hundreds of business cases if you test the behavior of the internal model differently. For example, something similar to integration testing: we write to the user stream, and already inside the adapter, Pusher or Ably we translate this stream into the name of the normal channel so as not to write it all into business logic.
Dependencies
In such a model architecture, many superfluous entities appear. Previously, we took some kind of Django function and wrote it: request, response, minimum actions. Here you need to initialize the Mappers, put in Stories and initialize, process the request line of the HTTP request, see which answer to give. All this results in 30-50 lines of boilerplate calling code Stories inside Django-view.
On the other hand, we have already written interfaces and Mappers. We can check their compatibility with a specific business case, for example, using the Dependencies library. How? Through the Dependency injection pattern, everything is declaratively glued to a minimal boilerplate.
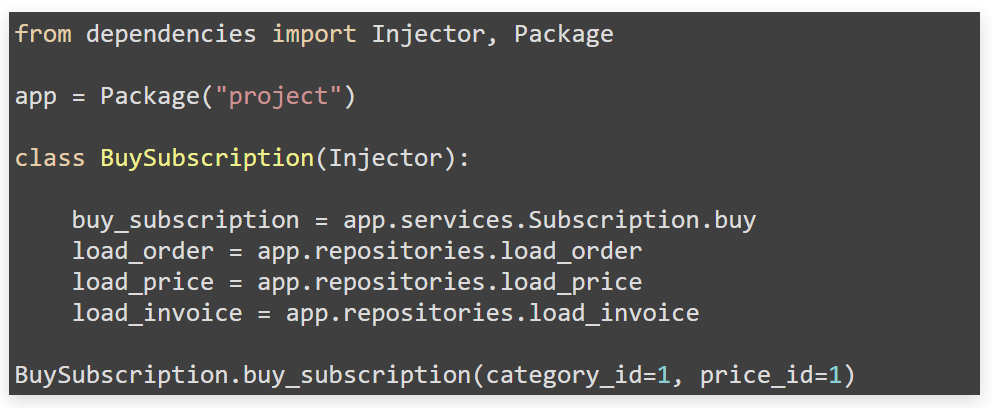
Here we specify the task to take a class in the services package, put three mappers in it, initialize the Stories object and give it to us. With this approach, the number of boilerplate in the code is reduced enormously.
Refactoring map
Applying everything I talked about, we developed a scheme by which we rewrote a large project from Django signals (implicit “callback hell”) to Django using DDD.
First step without DDD. At first we did not have DDD – we wrote MVP. Made our first money, invited investors, and convinced them to switch to DDD.
Stories without contracts. We broke the project into logical business cases without data contracts.
Contracts and aggregates. Then, one by one, we dragged the data contract for each model, which can be traced in our architecture.
Mappers. We wrote them to get rid of data warehouse templates.
Dependency Injection. Get rid of gluing patterns.
If your project has outgrown MVP and it urgently needs to be changed in architecture so that it does not slip into legacy – look towards DDD.

{kind=link}
{kind=link}