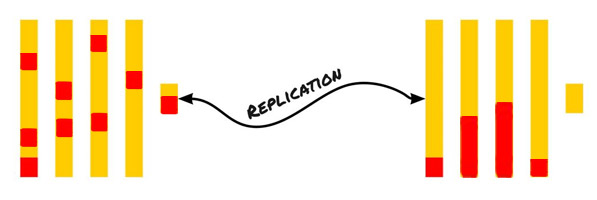
ClickHouse replication: expectation and reality
There is a lot of different information about ClickHouse, but let’s talk about how to prepare the infrastructure with it. It took us about six months to get it to work exactly the way it finally suits us. It was necessary to find an efficient configuration both in terms of money and in terms of the operation of the base as such.
At the time of this writing, the repository and the results of its work are used by 16+ teams (11+ analysts and 2 data scientists, 70+ developers, managers and managers).
Every day, the storage receives ~ 1.2 TB of data, users and automation for generating reports generate ~ 35,000 requests per day for samples of varying complexity.
We have gone from ClickHouse as a service with a cloud provider to our own installation, and until recently we had a ClickHouse cluster of five nodes without replication for more than a year and was deployed on a hyper-converged infrastructure with hybrid disks (SSD as cache + HDD), the installation had a number of problems:
- There was a risk of data loss if one of the nodes failed.
- There was no convenient data replication scheme.
- The unpredictable behaviour of disk performance and the impact on other virtual machines deployed on the cluster required greater isolation of the analytical load from other services of the company.
Data Loss Risk Protection
In case of loss, we could recover most of the data that was stored in ClickHouse from other sources (OLTP databases or S3), but this would take a significant amount of time, according to our estimates, about 1 week, because if you lose one server from the cluster, you need would restore the entire amount of data, which, of course, did not suit us or the business.
At this point, we had a mechanism for backing up data from ClickHouse, which did not always work stably, but even if it worked, it could guarantee cluster recovery within 1-2 days, but at the same time, we would have to restart all ETL and ELT processes in order to rewrite the data from the moment the backup was created until the failure of the cluster, which would also take a significant amount of time.
Therefore, it was decided to use the replication mechanisms in ClickHouse, which have significant difficulties in using, from the developer’s point of view, if you are used to mature RDBMSs such as PostgreSQL and MySQL.
Performance and resource issue
The analytical load from ClickHouse interfered with the operation of services that are sensitive to latency, so it was decided to immediately move it to a separate circuit on separate servers. The isolation offered by the hyper-converged infrastructure was not enough for us. The performance of hybrid drives (SSD + HDD) was lacking, they wanted to switch to SSD only.
By now, we understood that the new storage installation would last for at least a couple of years. We have a well-built team that maintains a fleet of servers; therefore, deploying ClickHouse on our hardware servers was cost-effective. We did not consider deploying in the clouds of the main installation, but we would like to be able to expand our installation if the need arises. Also, according to our experience, you have to spend less time on maintaining your own servers than on solving problems and various special effects in the clouds.
Selection and implementation
To protect against risks and avoid problems, we considered different options for configuring ClickHouse and where all this will live. We wanted to find a solution so that we would not have to redo it after six months and return to this issue again, because the storage is a rather conservative solution due to the many connections with it that appear during use.
As described above, we settled on our iron servers, since this was a cost-effective solution for us and eliminated the performance problems that we encountered earlier.
We knew in advance that we would have one or two ClickHouse experts, and 40-50 users. We wanted to isolate knowledge about the infrastructure, cluster and its topology from ordinary users. If you just need to create a table, here is a simple command for you, you do it through SQL and do not know how the cluster changes over time. Classic databases isolate this layer and provide a convenient toolkit to separate the role of the person who maintains the infrastructure and uses the infrastructure. All the necessary information is in the documentation, but it is difficult to extract pieces of it from it – because there is a lot of documentation, and not because it is bad. And the documentation assumes that you are an expert, after a couple of weeks of poking around, you can come out with knowledge. But our users shouldn’t do that. For them, we have an instruction that can be absorbed in 1 hour and work calmly.
And here ClickHouse has two features that solve these needs.
Using the cool ON CLUSTER mechanism, which is evolving and largely abstracts the user from understanding the cluster topology. For example, when creating tables, you do not need to execute the query yourself on all the nodes in the cluster.
Using distributed tables, when a user can access one table on any of the cluster nodes and receive all the necessary data on this table from the entire cluster, since under the hood of ClickHouse he will do everything himself.
Watching good practices
At the time of the creation of the cluster, we found only the experience of companies that offered to use circular replication. And this approach assumed that the code written by developers and analysts outside the team that maintains the storage needed to know the cluster topology, the distribution of nodes across physical servers. Which fundamentally did not suit us, because we strive to lower the entry threshold for storage users.
In short, replication looks like this: data from the first node should be replicated to the second, from the second to the third, and so on.
We already had experience with this approach and there were inconveniences with it.
To store replicas on one server, you need to use different databases (this configuration is well described in the article mentioned above). We cannot create replicated tables in the same database, since the main table on the same shard will be on the same path with the replica of the neighbouring shard. To solve this problem, you need to place tables in different databases, create two databases on each node, one of which will store the data of a specific shard, and the other – a replica of a neighbouring shard.
It will look somehow like this:
Shard # 1
db_shard_1
db_shard_2
Shard # 2
db_shard_2
db_shard_3
Shard # 3
db_shard_3
db_shard_1
You will have to create such tables on each shard separately.
Example of table creation queries for Shard # 1:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE TABLE db_shard_1.test_table_shard ( id UInt32, name String, cdate DateTime ) ENGINE ReplicatedMergeTree('/clickhouse/tables/db_shard_1/test_table_shard', 'replica_1') ORDER BY (id) PARTITION BY (cdate); CREATE TABLE db_shard_2.test_table_shard ( id UInt32, name String, cdate DateTime ) ENGINE ReplicatedMergeTree('/clickhouse/tables/db_shard_2/test_table_shard', 'replica_2') ORDER BY (id) PARTITION BY (cdate); |
The disadvantage of this approach is that all created replicated tables in the cluster will be located only in certain databases. There is no way to restrict access rights to certain databases.
To create a distributed table on top of replicated tables, as a configuration parameter, you need to specify the name of the base and the table, which must be the same on all nodes. For this to work, you need to define a default database for each node in the shard; this can be done by adding the <default_database>...</default_database>.
parameter to the configuration of each node.
After defining the default_database, when creating a distributed table, you can omit the name of the database, since the value will be substituted from the config.
|
1 2 3 4 5 6 7 |
CREATE TABLE default.test_table ( id UInt32, name String, cdate DateTime ) ENGINE = Distributed('test_cluster', '', 'test_table_shard', rand()); |
When creating tables, you can use macros with specific values for each node.
Developers added macros:
{database} – expands to the name of the database.
{table} is the name of the table.
Macros added by us (repository administrators) to the config:
{shard} – shard identifier.
{replica} – replica name.
Such macros are convenient to use to create tables using ON CLUSTER, you can execute one query, and the necessary tables will be created on all nodes. But with circular replication there is a problem, since the tables are in different bases, presumably, such a query should create all the necessary tables:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE test_table_shard ( id UInt32, name String, cdate DateTime ) ENGINE ReplicatedMergeTree('/clickhouse/tables/{database}/{shard}/{table}', '{replica}') ORDER BY (id) PARTITION BY (cdate); |
But we will receive a warning that we need to explicitly specify the base in which the table is created, in this regard, it is not possible to create all the necessary tables with one query.
Code: 371, e.displayText () = DB :: Exception: For a distributed DDL on circular replicated cluster its table name must be qualified by database name. (version 21.4.3.21 (official build))
You can, of course, execute a query on each pair of replicated nodes, but for this you need to know the cluster topology.
It takes a lot of manual steps to restore a node. The main inconvenience is that there is no way to pull the actual metadata of tables from / var / lib / clickhouse / metadata / from a neighboring node, since there is no other node on which exactly the same tables would be created. We have to look at the configuration and, in accordance with it, edit the metadata for the new node.
When adding a new node, you will need to manually transfer the replicas so that there is no situation that two replicas are on the same server. It turns out that the replica for Shard # 3 will move from Node # 1 to Node # 4.
There is also a difficulty with resharding partitions, since ClickHouse does not provide this automatically. For these purposes, you can use the СlickНouse-copier utility.

{kind=link}
{kind=link}