CI / CD using Jenkins on Kubernetes
Here are already several articles on our website about jenkins, ci / cd and kubernetes, but in this I don’t want to concentrate on analyzing the capabilities of these technologies, but check their simplest configuration for building the ci / cd pipeline.
I hope that the reader has a basic understanding of Docker, and I will not dwell on the topics of installing and configuring kubernetes. All examples will be shown on minikube, but can also be applied on EKS, GKE or others, without significant changes.
Environments
I suggest using the following environments:
- test – for manual deployment and branch testing
- staging – an environment where all changes that fall into master are automatically deployed
- production – the environment used by real users, where changes will only go after confirming their operability on staging
The environments will be organized using kubernetes namespaces within the same cluster. This approach is as simple and fast as possible at the start, but also has its drawbacks: namespaces are not completely isolated from each other in kubernetes.
In this example, each namespace will have the same set of ConfigMaps with the configurations of this environment:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
apiVersion: v1 kind: Namespace metadata: name: production --- apiVersion: v1 kind: ConfigMap metadata: name: environment.properties namespace: production data: environment.properties: | env=production |
Helm
Helm is an application that helps to manage resources installed on kubernetes.
To get started, you must initialize the tiller pod to use helm with the cluster:
|
1 |
helm init |
Jenkins
I will use Jenkins as it is a fairly simple, flexible and popular platform for building projects. It will be installed in a separate namespace to isolate itself from other environments. Since I plan to use helm in the future, it is possible to simplify the installation of Jenkins using the existing open source charts:
|
1 |
helm install --name jenkins --namespace jenkins -f jenkins/demo-values.yaml stable/jenkins |
demo-values.yaml contains the Jenkins version, a set of pre-installed plugins, a domain name and other configuration
This configuration uses admin / admin as the username and password for login, and can be reconfigured later. One of the possible options is google SSO (google-login plugin is required for this, its settings can be found in Jenkins> Manage Jenkins> Configure Global Security> Access Control> Security Realm> Login with Google).
Jenkins will be immediately configured to automatically create one-time slaves for each assembly. Because of this, the team will no longer expect a free agent for assembly, and the business will be able to save on the number of required servers.
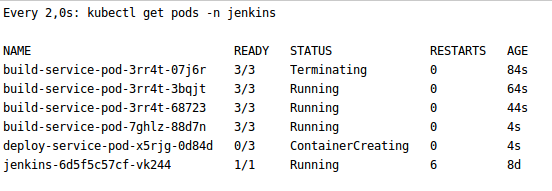
Also out of the box, PersistenceVolume is configured to save pipelines for restarting or updating.
For the automatic deployment scripts to work correctly, you need to give cluster-admin permission for Jenkins to get a list of resources in kubernetes and manipulate them.
|
1 |
kubectl create clusterrolebinding jenkins --clusterrole cluster-admin --serviceaccount=jenkins:default |
In the future, you can update Jenkins using helm in case of new versions of plugins or configuration changes.
|
1 |
helm upgrade jenkins stable/jenkins -f jenkins/demo-values.yaml |
This can be done through the interface of Jenkins itself, but with helm you will have the opportunity to roll back to previous revisions using:
|
1 2 |
helm history jenkins helm rollback jenkins ${revision} |
Application assembly
As an example, I will build and deploy the simplest spring boot application. Similarly with Jenkins I will use helm.
The assembly will have the following sequence:
- checkout
- compilation
- unit test
- integration test
- artifact assembly
- artifact deployment in docker registry
- deploying artifact to staging (only for master branch)
For this I use the Jenkins file. In my opinion, this is a very flexible (but, unfortunately, not the easiest) way to configure the project assembly. One of its advantages is the ability to keep the configuration of the project assembly in the repository with the project itself.
Сheckout
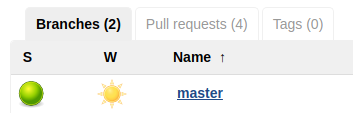
In the case of bitbucket or github organization, you can configure Jenkins to periodically scan the whole account for the presence of repositories with Jenkinsfile and automatically create assemblies for them. Jenkins will collect both: master and branches. Pull requests will be displayed in a separate tab. There is a simpler option – add a separate git repository, regardless of where it is hosted. In this example, I will do just that. All you need is in the Jenkins> New item> Multibranch Pipeline menu, select the assembly name and bind the git repository.
Compilation
Since Jenkins creates a new pod for each assembly, in the case of using maven or similar collectors, the dependencies will be downloaded again each time. To avoid this, you can select PersistenceVolume for .m2 or similar caches and mount it in the pod that builds the project.
|
1 2 3 4 5 6 7 8 9 10 11 |
apiVersion: "v1" kind: "PersistentVolumeClaim" metadata: name: "repository" namespace: "jenkins" spec: accessModes: - ReadWriteMany resources: requests: storage: 10Gi |
In my case, this allowed to speed up the pipeline from about 4 to 1 minute.
Versioning
For CI / CD to work correctly, each build needs a unique version.
A very good option would be to use semantic versioning. This will allow you to track compatible and incompatible changes, but such versioning is more difficult to automate.
In this example, I will generate a version from id and the date of the commit, as well as the name of the branch, if it is not master. For example 56e0fbdc-201802231623 or b3d3c143-201802231548-PR-18.
Advantages of this approach:
- ease of automation
- it’s easy to get the source code and its creation time from the version
- visually you can distinguish the release version of the candidate (from the wizard) or experimental (from the branch)
but:
- this version is harder to use in oral communication
- it is not clear whether there were incompatible changes.
Since docker image can have several tags at the same time, approaches can be combined: all releases use the generated versions, and those that fall on the production are additionally (manually) tagged with semantic versioning. This, in turn, is associated with even greater implementation complexity and the ambiguity of which version the application should show.
Artifacts
The result of the assembly will be:
- docker image with an application that will be stored and loaded from the docker registry. The example will use the built-in registry from minikube, which can be replaced by a docker hub or a private registry from amazon (ecr) or google (do not forget to provide credentials to them using the withCredentials construct).
- helm charts with a description of the deployment of the application (deployment, service, etc) in the helm directory. Ideally, they should be stored on a separate repository of artifacts, but, for simplification, they can be used by checking out the necessary commit from git.
Jenkinsfile
As a result, the application will be built using the following Jenkinsfile:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
def branch def revision def registryIp pipeline { agent { kubernetes { label 'build-service-pod' defaultContainer 'jnlp' yaml """ apiVersion: v1 kind: Pod metadata: labels: job: build-service spec: containers: - name: maven image: maven:3.6.0-jdk-11-slim command: ["cat"] tty: true volumeMounts: - name: repository mountPath: /root/.m2/repository - name: docker image: docker:18.09.2 command: ["cat"] tty: true volumeMounts: - name: docker-sock mountPath: /var/run/docker.sock volumes: - name: repository persistentVolumeClaim: claimName: repository - name: docker-sock hostPath: path: /var/run/docker.sock """ } } options { skipDefaultCheckout true } stages { stage ('checkout') { steps { script { def repo = checkout scm revision = sh(script: 'git log -1 --format=\'%h.%ad\' --date=format:%Y%m%d-%H%M | cat', returnStdout: true).trim() branch = repo.GIT_BRANCH.take(20).replaceAll('/', '_') if (branch != 'master') { revision += "-${branch}" } sh "echo 'Building revision: ${revision}'" } } } stage ('compile') { steps { container('maven') { sh 'mvn clean compile test-compile' } } } stage ('unit test') { steps { container('maven') { sh 'mvn test' } } } stage ('integration test') { steps { container ('maven') { sh 'mvn verify' } } } stage ('build artifact') { steps { container('maven') { sh "mvn package -Dmaven.test.skip -Drevision=${revision}" } container('docker') { script { registryIp = sh(script: 'getent hosts registry.kube-system | awk \'{ print $1 ; exit }\'', returnStdout: true).trim() sh "docker build . -t ${registryIp}/demo/app:${revision} --build-arg REVISION=${revision}" } } } } stage ('publish artifact') { when { expression { branch == 'master' } } steps { container('docker') { sh "docker push ${registryIp}/demo/app:${revision}" } } } } } |
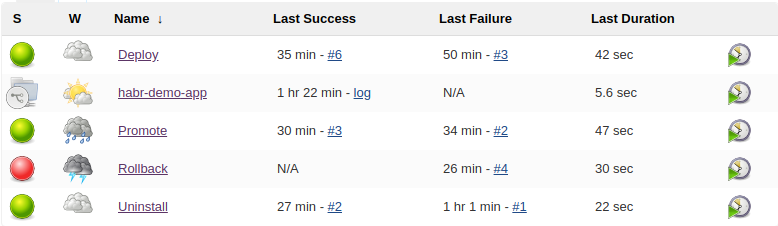
Additional Jenkins pipelines for application lifecycle management
Let’s imagine, that the repositories are organized so that:
- contain a separate application in the form of docker image
- can be deployed using helm files, which are located in the helm directory
- are versioned using the same approach and have a helm / setVersion.sh file for setting revisions in helm charts
Then we can build several Jenkinsfile pipelines to manage the application life cycle, especially:
- deployment to any environment
- removal from any environment
- promote with staging on production
- rollback to previous version
In the Jenkinsfile of each project, you can add a deploy pipeline call that will be executed each time the master branch is successfully compiled, or when the deploy branch explicitly requests the test environment.
Thus, it is possible to build a continuous deployment on the selected test or combat environment, also using jenkins or its email / slack / etc notifications, have an audit of which application, which version, by whom, when and where it was installed.
Conclusion
Using Jenkinsfile and helm, you can simply build ci / cd for your application. This method may be most relevant for small teams that have recently started using kubernetes and are unable (regardless of the reason) to use services that can provide such functionality out of the box.


{kind=link}
{kind=link}
{kind=link}